
Public Domain image from piqsels.com
Science of Chess: A g-factor for chess? A psychometric scale for playing ability
How do you measure chess skill? It depends on what you want to know.
Ah, ratings.
As I write this, my ratings on Lichess are numbers I'm fairly happy with: I'm just above 1800 in Rapid, just above 1700 in Blitz, and a little north of 1500 in Bullet. I try not to focus on my rating so much when I play, but as I'm guessing may be the case for many of you, I lose that battle more often than not. A few losses in a row can easily push me to a century border, for example, and it just sort of bugs me until I can get myself back up out of the lower numbers. Likewise, if I'm in the middle of a decent climb and start creeping close to a new milestone, it's hard not to get a little tense about what I perceive as a sort of promotion chance. Could I be a solid 1900 rapid player after all? Is 2000 within reach?
I think about (and worry over) my rating because it offers a chance to answer the question on the mind of most chess players: How good am I? Performance statistics of all kinds draw interest because they promise a way to turn a subjective opinion about player ranking and ability into an objective measurement. If you're a data geek (and even if you're not), that also means you can spend as much time as you like arguing about what a particular statistic leaves out, or how it systematically underrates some players (especially me - I'm MUCH better than my rating, I promise), or any other feature of the estimation procedure you feel like tinkering with.
I think Elo ratings are interesting to think about from a cognitive (and in this case, maybe a neuropsychological) perspective, too. I say this because it's often the case that a cognitive scientist or a neuropsychologist is faced with the same problem that someone designing a chess rating system faces: How do I quantify a person's abilities with regard to a complex process? In my own lab, we have a small library of common neuropsychological tests that are supposed to provide answers to this question for a wide range of cognitive processes: We have the Embedded Figures Test on order so we can test participants' abilities to detect patterns that are part of a larger configuration. We have the Proteus Mazetests to measure planning and decision-making during a wayfinding task. We've got Ishihara plates to assess color vision and we use the Cambridge Face Memory Test to screen for prosopagnosia. Each of these is a way to condense a person's capabilities into usually just one number that we use to more or less rank people: Are you an 80th percentile recognizer of faces, or are you below the 2nd percentile (at which point we'd probably confidently say you're faceblind)? How did you do on those Ishihara plates? If you did especially poorly on one of the key subsets, I'll feel comfortable saying that you've got red-green color blindness.

A good test can help us understand and characterize performance in a specific setting. The Ishihara plates are an excellent means of assessing color vision via a quick and intuitive assessment. See page for author, CC BY 4.0 <https://creativecommons.org/licenses/by/4.0>, via Wikimedia Commons
Compared to these kinds of assessment, however, Elo is different in some crucial ways. What I'm going to do in the rest of this post is briefly talk about what Elo is (and how it is calculated) and then take a look at a paper that offers an approach to measuring playing strength that looks more like the neuropsychological assessments I listed above. My hope is that this is an interesting chance to think about what we mean when we say someone is a strong player and how different kinds of measurement may offer complementary answers to the question of how good we are at chess.
A brief history (and description) of Elo
An important caveat before we begin: I am but a humble cognitive scientist who uses statistical tests of various kinds to describe the results of the experiments we run in the lab. That does not make me a proper statistician nor any kind of real expert in statistical methods. I don't think I've met a colleague yet who didn't wish that they knew more about statistics and I am squarely in the same camp. I've got a decent amount of mathematics under my belt, but there are many people who know a lot more than me about the topic. This means there is a decent chance I may be about to go a little astray while describing Elo in a manner that a real statistician may disagree with, and they'd probably be right. If you are such a statistician, please feel free to weigh in down in the forum, but be gentle. :) Also, this is a pretty deep rabbit hole if you want to explore and I certainly don't intend to cover every nuance of how ratings work. That's not to minimize the importance of the topics I'm going to avoid, but in service of making this an article that helps introduce some of the features of rating systems that I think are interesting to know about broadly. If this seems a little elementary, that's because it's sort of intended to be.
So what is your Elo rating supposed to do, anyway? It's easy to think about Elo in terms of an individual player's strength, but it's important to keep in mind that it is also intended to offer a way of predicting what will happen when two players face each other. Specifically, ratings are meant to be useful because the difference in two players' rating should be a good estimate of how likely it is that one player will beat the other. Unlike your typical neuropsychological test of some cognitive ability, Elo is estimated comparatively rather than in terms of assessing an individual. The underlying model is thus based on assumptions regarding pairs of players rather than how individual ability varies over the population.
Building an individual rating system from assumptions about player-pair outcomes.
What are those assumptions and how do we use them to estimate Elo? The bare minimum that I think you need to understand the nature of Elo ratings are the following ideas about how a rating should work in terms of predicting match outcomes, which lead to a strategy for estimating/adjusting a rating based on what actually happens after people play games together and win, lose or draw:
- When two players meet, the higher-rated player should be more likely to win.
- The probability that a higher-rated player will win should increase as the rating difference between players increases.
- What exactly should that relationship look like? Let's use a normal distribution as our underlying model. This essentially means that when a rating difference is zero, we have equal probability mass for either playing winning. As rating differences become positive, the probability for the higher-rated player winning starts to increase according to the integral of that bell-curve, asymptotically approaching 1 as the difference continues to grow. This means there is always a chance that the weaker player will win, but it becomes vanishingly small as the rating difference gets larger.
Below you can see how this third assumption translates into probabilities for winning (the expected outcome) vs. losing (the unexpected outcome) for the higher-rated player as a function of rating difference.
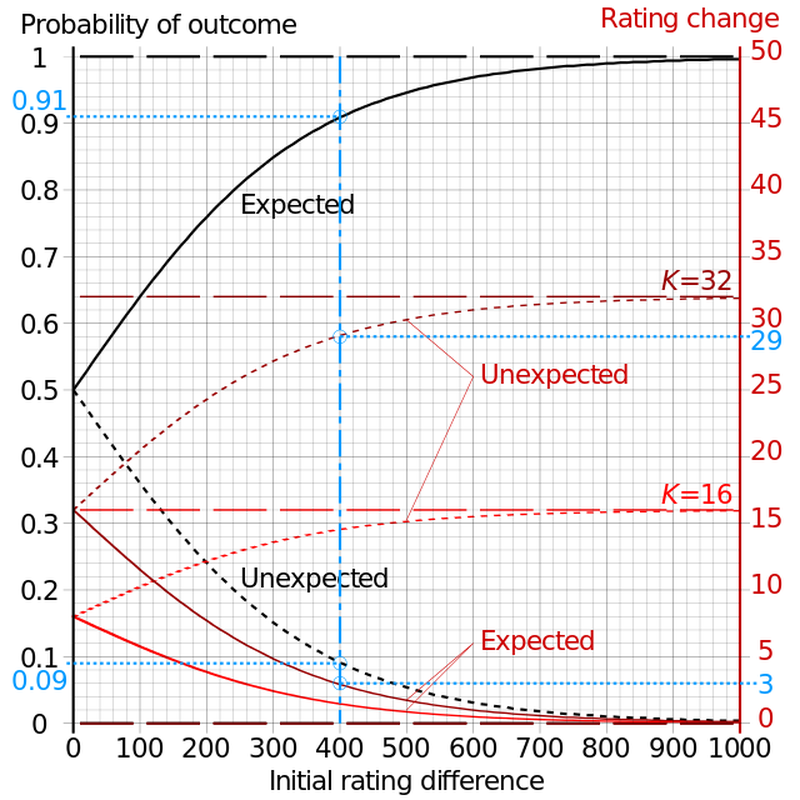
These graphs show you how winning becomes an increasingly long shot for a weaker player as the rating difference between players grows. Cmglee, CC BY-SA 3.0 <https://creativecommons.org/licenses/by-sa/3.0>, via Wikimedia Commons
Using matches to update Elo (according to more assumptions!)
Many of you are probably already familiar with the recipe for calculating your Elo rating, but in case you haven't ever really thought about it, here is the gist. The difference between your rating and your opponents' ratings in a tournament serves as a way to predict what your score should be after playing games with them. That is, we can look at a graph like the one above and use it to come up with a predicted outcome for you against each of your opponents based on the underlying probability distribution. The funny thing about this estimate is that we ignore the fact that a real game always results in a win (value 1) a loss (value 0) or a draw (value 1/2) and insead admit any value between 0 and 1 into our prediction. Are you about 50 points higher-rated than your opponent? You should win about 58% of the time, so our prediction for that game is that you score a 0.58. Are you 100 points lower rated? Than your predicted score is about 0.36. After we read all of these from our graph (or more likely, use an app for that), we add them all up to get your total predicted tournament score.
The only thing left to do is find out what actually happens! The logic here is not unlike the adaptive staircase I discussed in my previous post: We started with a guess about what your rating should be and we used it to predict your tournament score against some opponents. Depending on how wrong we were about that score (and in which direction), we'll change our guess about your rating based on the new data. Hopefully this helps us arrive at a better rating estimate that we can use to better predict what will happen the next time. Ideally, it would be great if this adjustment helped us converge on a value we might call your true rating. So how does that adjustment work? First, a formula, then a little bit of unpacking.
New ELO = Old ELO + (K * (Wins−WinsExpected))
What do these terms mean? Hopefully "New ELO" and "Old ELO" are self-explanatory. "WinsExpected" is that summed set of predicted scores that I described above. "Wins" refers to your actual score in the tournament based on the wins, losses, and draws you achieved. Using the difference between the actual outcome and the predicted value this way means that doing better than we thought you would will make your rating go up, but doing worse will make it go down. Finally, what about that "K"? K is sort of interesting because it's basically a numerical dial we can use to play around with how sensitive your rating will be to the new information we gain from your games: If K is high, then your rating will change a lot based on discrepancies between our predictions and reality. If it is low, then your rating won't budge very much. So how do you choose this value? This is one of those cases where there isn't just one right answer - it's more about choosing something that makes the system work in a way that you like. The USCF lets K vary as a function of rating between 3 values: 32, 24, and 16. FIDE lets it vary between 40, 20, and 10. In both cases, K is adjusted so that higher ratings are less volatile.
There are other features of this model we could mess around with if we wanted. One that turns out to be important is the underlying assumption about how probability is distributed as a function of rating difference. I said up above that a normal distribution seemed sensible, but there's a funny caveat: Lower-rated players turn out in practice to have a better shot at winning than the normal distribution gives them credit for! This means that a distribution with "heavier tails" (the technical term is higher kurtosis) is a little better to use, so the logistic distribution turns out to be how multiple organizations work with Elo. You can see what that difference looks like in the figure below. A subtle difference? Maybe, but every little bit helps.
 The difference between the tails of a normal distribution (dashed green line) and a logistic distribution with the same moments. Benwing, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
The difference between the tails of a normal distribution (dashed green line) and a logistic distribution with the same moments. Benwing, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
If you like thinking about this sort of thing, you can go check out the Wikipedia page about chess rating systems, which will lead you to all kinds of interesting alternatives like the Harkness rating system, The English Chess Federation system, and the Glicko system. While these share a common set of underlying principles about estimation and adjustment, they each incorporate different assumptions about the relationships between rating, outcome, and other features of play that lead to distinct tools for assessment. There is also all kinds of neat stuff about rating "floors" and how they're determined that you can read about, as well as the reasoning behind the different values of K used in different systems, and so on, et cetera, etc.
Except...I think it's not entirely right to say that these are really assessments of chess ability, per se. Sure, they're tools for establishing rankings and helping one come up with expectations about player matches, but the Elo rating you have as an individual (or the Glicko rating, or the ECF rating) is sort of a by-product. You can use it as a proxy for evaluating an individual's ability, but unlike the neuropsychological assessments I described above, we're using the very fluid world of matches and tournaments as a way to get that measurement. When we talk about evaluation in the neuropsych context, there is a lot of emphasis on concepts like reliability (will your evaluation yield consistent results across different contexts?), validity (does your evaluation measure the process you intend it to?) and norming an evaluation with respect to a target population. We also tend to emphasize keeping testing conditions uniform as much as possible, so that we can be confident that the assessment itself determines performance, not variability in how the assessment is administered. While we all sure play a lot of chess, our playing histories are very different, which I think makes it tough to understand exactly what Elo means in terms of your abilities - it gives you a decent sense of who you can probably beat, but that doesn't seem quite the same as measuring what you can do. Regardless of whether you agree with this perspective or not, what I'd like to do next is introduce you to an attempt to come up with an evaluation of playing strength that looks a little more like the tools I described above for measuring cognitive and perceptual abilities. This will give us a chance to think about how one might go about measuring chess ability without using competition between players to guide us and also to see what goes in to developing an assessment tool like this.
The Amsterdam Chess Test (van der Mass & Wagenmakers, 2005)
Do we need a proper psychometric assessment of chess playing strength? I just hinted that I thought Elo was a funny way to go about it for...reasons...but you may be feeling skeptical about the idea that we can't just use rating and call it a day. Here are a few things to think about though, to expand on the rationale for developing such a test.
- I stopped playing competitive chess when I was about 14 and then started playing again in my 40's. Before my first OTB tournament, I couldn't help but wonder if that old USCF rating had anything to do with how I'd play now - was I 30 years wiser or dimmer? My attention span was probably a lot better than in my teens, but I was I just also a little less likely to look for and see creative moves? The only way to really find out is to go play a bunch of rated games to see what happens, but a psychometric test might help a player estimate their ability without the need to book up a busy playing schedule.
- Ostensibly, chess skill depends on different underlying abilities (though this is an interesting question in and of itself) and many psychometric tests incorporate subscales that are intended to isolate specific contributing processes. Elo as an individual evaluation only tells you about likelihood of winning, but doesn't reveal much about your strengths in particular sub-domains.
- Finally, and stop me if this seems circular, chess is a really useful domain for thinking about our approach to a lot of other cognitive problems given all the data that we have about player ratings, etc. There is a suite of psychometric techniques we typically employ to develop new assessments, but in most cases we don't have much of an established benchmark to compare those to - while Elo might not satisfy everything we'd like out of an assessment of playing strength, it's also a strong quantitative point of comparison we can use. In a way, this means we get a neat data point about how well those standard psychometric approaches tend to work from seeing how they compare to an established tool. The reason I don't think this amounts to a truly circular argument is that we're not trying to replace or invalidate ratings, but instead developing an alternative approach to measuring chess ability.
If you like this as a rationale for trying to make such a test, the next question is how we actually do it. The answer is that we more or less try to identify things we can ask our participants to do that we think will be reliable, will be valid, and also be practical in terms of testing time and ease of use. After that, our. job is to see what happens in some target population to actually see if the tasks we came up with have good psychometric properties. Modulo all the in-depth reporting you'll get from the full paper (see the References for a link) that's more or less what van der Maas and Wagenmakers did, so let's start by talking about the tasks that they selected and why they thought these were useful to include.
Components of the ACT
There are 5 parts to the ACT, each one introduced to target some specific aspect of chess playing ability.
Choose-a-move (A and B)
They describe the "core" of their assessment in terms of two different versions of what they call a "choose-a-move" task, which will look very familiar to all of you whether you've read previous posts in this series or not. This is a "best move" judgment with specific problems chosen to emphasize tactical and positional themes as well as endgame knowledge. You can see an example below, which a participant would have to try and solve (for White in all cases) within a 30-second time limit.
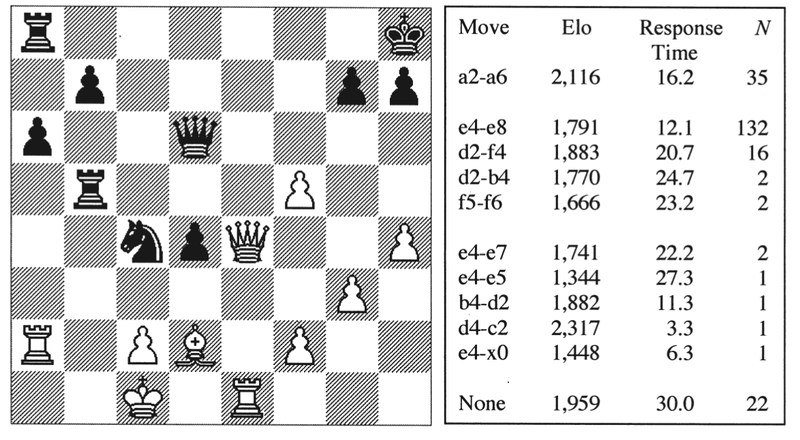
Figure 2 from van der Maas and Wagenmakers, 2005, illustrating their Choose-a-move task. In this case, a2-a6 (or Rxa6 if you prefer) is the best solution.
Predict-a-move
Y'know the thing about choose-a-move tasks, though? These kinds of scenarios where there is a single best move that stands above the rest aren't the most representative of what happens during regular play. For lack of a better way to put it, they're sort of "puzzle-y," which isn't the only kind of situation that happens while you're making moves. Sure, sometimes you've got to be able to spot a crucial play, but in many cases you have a number of decent moves that might each help you achieve some progress towards a meaningful sub-goal, or be fairly equally competent defensive strategies, or be roughly equivalent for other reasons. To help round out their assessment with positions that weren't so dramatically balanced on the knife's edge, the authors also included what they called a predict-a-move judgment. In this task, a participant will still be presented with a position, but this is drawn from a real game and your job is to guess what comes next. What I find kind of fascinating about this part of the test is that when I say "drawn from a real game," I mean a single real game! All of the items on this part of the test come from Liss-Hector, Copenhagen 1986 and participants basically tried to predict the game in sequence. You get to see a position from the game, you guess what comes next, then you're shown what actually did come next and you have to guess the next step, and so on. This makes it wicked important to make sure your participants don't know this game on the way in to the test!
Recall test
Besides these two different kinds of next-move testing, the authors include some other tasks that are a little more abstract in nature, but selected to probe other aspects of chess knowledge and ability. Another familiar one (especially if you read my spatial cognition post) is a recall test for positions: You get to see a chess position that's either "typical" (very likely to emerge from normal play), "not typical" (possible, but not a position that emerges regularly), and "random" (scrambled pieces that don't correspond to regular play in a meaningful way) and are asked to study the position, then indicate what piece was in a probe square shown to you afterwards. We know from prior work that strong players tend to have a memory advantage for real positions, but not scrambled ones, so these items seem like potentially good ways to test some domain-specific chess memory ability. Besides the typicality of a the configuration, the items also vary in terms of how many pieces are in the position and whether the probe square was in the central part of the board or out towards the edges. These are mostly ways to further try to titrate item difficulty in systematic ways.
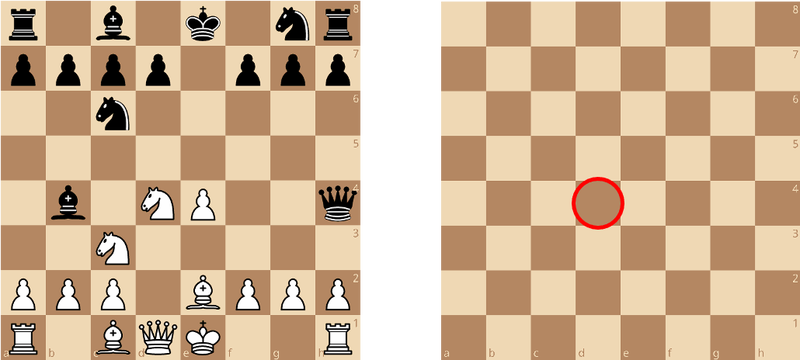
A schematic view of how the Recall test in the ACT works: First you study a position, then after it is removed you are asked to say what piece was in the indicated square. In this case, the right answer is to recall that a knight was here. Image by the author (and not an item used in the ACT).
Verbal knowledge test
I find this one particularly interesting because my intuition is that very little of my own chess ability is instantiated this way (which is maybe a problem? I guess we'll see!). This part of the test was made up of a series of verbal statements about chess, some about positional concepts, some about endgames, and some about openings, each presented with multiple-choice responses that participants were asked to select the right answer from. For example, something like "In the Lucena position, what must be true of the attacking rook?" That one wasn't in the ACT as far as I know, but knowing that "the attacking rook must cut off the opposing king by a file" would be the kind of thing you'd want them to find in the multiple choice items. An additional few items were intended to engage visualization by asking questions about knight paths on the board, etc.
Motivation assessment
Finally, the last part of the ACT to mention is the motivation questionnaire that they included that is less about specific abilities and more about how you approach the game in terms of your feelings while playing. Participants were asked to endorse items like "I enjoy overpowering my opponent." and similar statements to yield a profile regarding motivating factors that supported chess playing.
Population characteristics
So this is how the test is structured - now who do we get to try it out? The authors recruited a sample of 259 Dutch chess players at a specific tournament held in 1998 and you can see below how their Elo ratings compared to a much larger sample of players (everyone in the Dutch Chess Federation at the time).
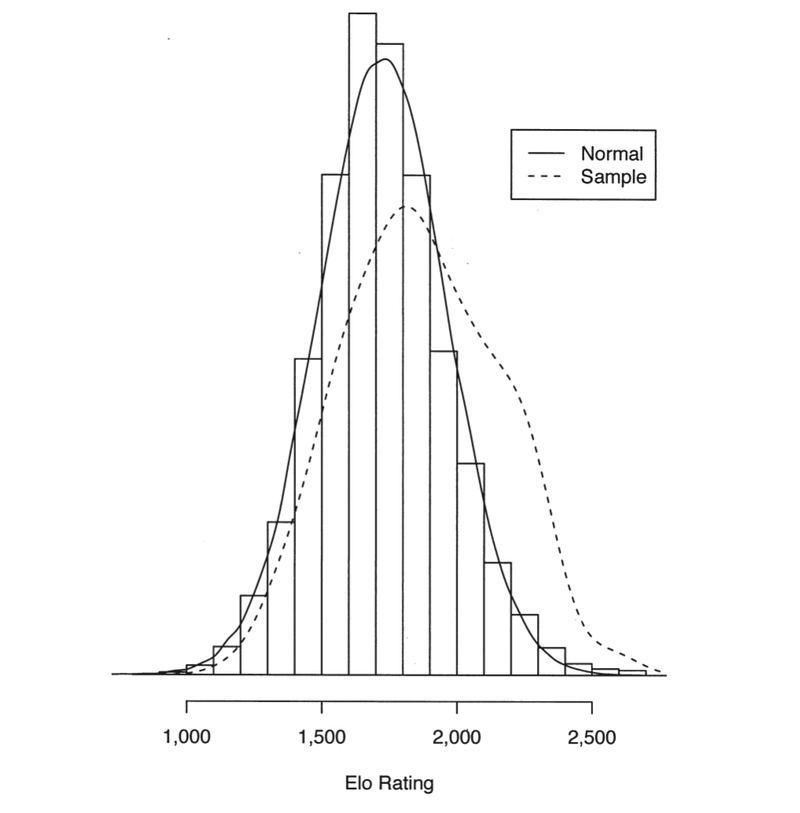
The distribution of Elo ratings in the sample used in the ACT study compared to the ~9000 members of the Dutch chess federation (Figure 1 from van der Maas and Wagenmakers).
The participants in their sample completed the ACT in about 1-hour in between rounds of a tournament and they have some interesting things to say about using the tournament outcomes as an interesting variable to consider relative to the psychometric data. This is already getting long (even for a Science of Chess post) so I'm going to focus on just two psychometric properties of the ACT that I think are particularly interesting: The factor structure and the validity. If you're a big fan of reliability...sorry!...but it was good. Like, really good. Well, really good in some spots and sort of medium-good in others. You can check out the paper.
Factor structure of the ACT
We set out to come up with a way to measure "chess ability" but to what extent is that a meaningful singular property of a chess player? Factor analysis offers a data-driven way to answer questions like this, and if you'd like a longer description of what it is and how it does what I'm about to describe, I'd encourage you to check out one of my first Science of Chess posts about Blitz, Bullet, and Rapid chess relative to Puzzle ability. For now, the nutshell version is that Factor Analysis is a way of looking at correlations (and the absence of correlations) across many different tasks to try and decide how many unique mechanisms we require to account for all the variation we see across different people who try all the tasks. If it turns out that people who are better at one task tend to also be better at all of the others, that would be an indicator that we need just a single factor to explain the data (a "g-factor" for our target ability, if you will). On the other hand, if it turns out that there is one subset of tasks that all strongly correlate with one another (but not the remaining measures) and the rest of the tasks also strongly correlate with each other (but not the first batch), that would suggest there are two underlying processes that dictate how you'll do.
In this case, the authors walk through two different versions of factor analysis applied to their data: One applied to the main tasks I described above and a second applied to all of the subscales considered as separate datapoints. While the former yields a single factor on which everything loads (a hint of general "Chess IQ"), the latter yields the following multi-factor structure.
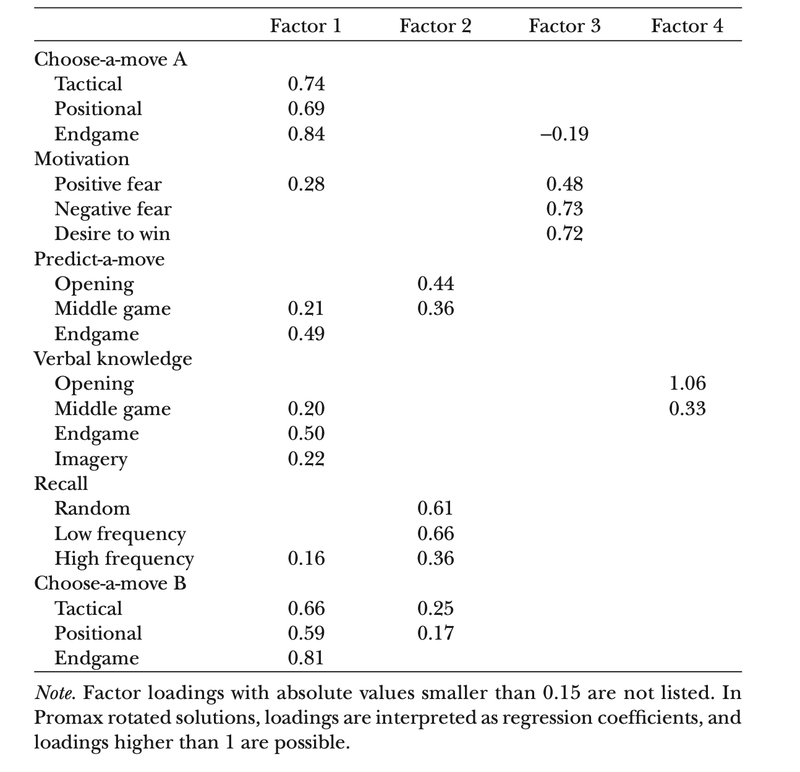
Table 4 from van der Maas and Wagenmakers, 2005 - each column contains the subscales that loaded onto each factor obtained from their factor analysis of all subscales of the ACT.
The first thing to take away from this table is that the magic number appears to be 4, which in itself is a neat little data point to know. The second, and more interesting, part is looking at which tasks loaded together onto the same factor as a way of seeing what kinds of core chess abilities the ACT measures (and which ostensibly have something to do with being a strong chess player). Look at all those tasks in the first column - what do they have in common? What about the second column? What's kind of neat to see is how some things that we might expect to go together don't (verbal knowledge and recall? Those both seem like chess memory to me, but they load onto different factors!) and other things that do go together that are maybe a little surprising. The authors argue that their first factor is mostly about assessing tactics and positional play, while the second one is more specifically about memory for chess. The trailing factors in Columns 3 and 4 are a little tougher to interpret by virtue of having only a few loadings, but it sure looks to me like all the motivational stuff is kind of off on its own.
What I love about this is that this gives us the kinds of interesting insights into cognitive mechanisms that we don't get from Elo. Again, this isn't to say that we have to give up our ratings, but it's neat to see how we can use the psychometric approach to ask questions about the structure of the chess-playing mind rather than just asking how we match up against other players.
Validity - How does the ACT relate to Elo?
Remember up above when I said Elo offered a neat chance to compare our shiny new psychometric scale to something quantitative? Let's cash in those chips, dear reader, and use correlations between players Elo ratings and their ACT performance to see how the latter stacks up. Does better ACT performance have anything to do with your rating?
The authors did a ton of neat stuff here that I'd encourage you to go dig into if you're interested to learn more, but I'll focus on what I think is the most straightforward and impressive part of their analysis: A presentation of how ACT performance in 1998 correlated with player Elo across 10 years (!) centered on 1998. As you can see in their figure below, these correlations are in general pretty good, though there is also considerable variability across the subscales.
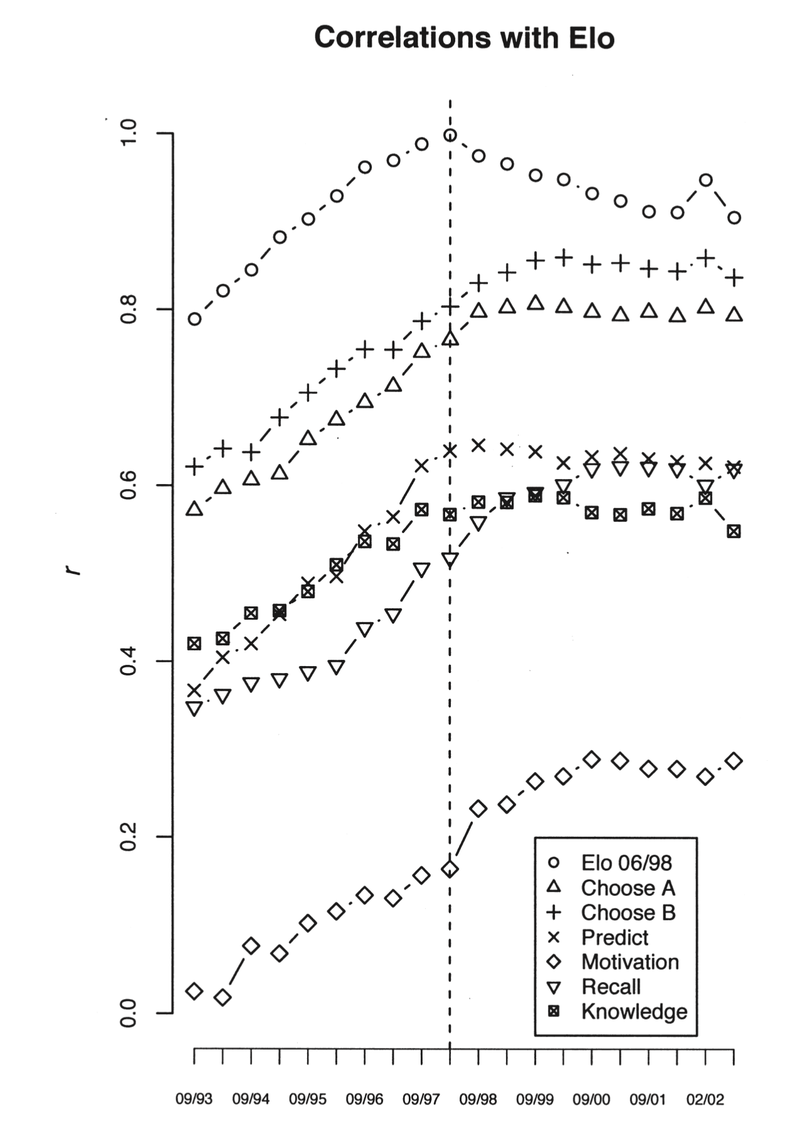
Figure 5 from van der Maas and Wagenmakers, 2005. Correlations of the different subscales in the ACT with ELO over time.
Where does all this leave us? The authors conclude (and I certainly agree) that it leaves us with a nice psychometric tool for measuring how good you are at chess that is valid, taps multiple different kinds of chess ability, is practical to administer, and that the analysis of this test with a target population of chess players reveals meaningful factor structure suggesting that "choose-a-move" judgments and to a lesser extent, chess memory tasks, are powerful and simple means of quickly assessing a player's strength.
Now look, this is where a number of people (including students in my typical Neuropsychology class) might stop and say "I knew it all along - totally obvious! Why did they bother doing this? Why did you bother writing all this about it?" I want to emphasize here at the end, that this is the stuff of cognitive/psychological research about chess rather than identifying ways to improve your chess play, and it's necessary to do work like this to characterize what your mind does when it plays chess or completes any complex task. Also, there are a ton of neat little insights in this paper based on their data that are totally worth reading about on your own if you like this idea of scale development and data mining to understand performance characteristics. In many ways, cognitive science is about working out the joints at which we should carve the mind, and the ACT is both a complementary way to assess chess playing skill and a way to gain some insights into the mental processes that contribute to play. I'm still going to obsess about my Elo, but I think the ACT may feature in my upcoming Neuropsychology class for the lesson it provides in how to try and measure complex human behavior.
I hope this was an interesting look at how we talk and think about measuring chess ability in different ways and for different purposes. I'm still deciding what to cover next and also have some upcoming travel that may mean there is a bit of a break between this post and the next one. In the meantime, I'm always happy to hear suggestions for topics you think would make for an interesting article or to hear ideas about the stuff I've covered already. Thanks as always for reading and see you in the next one!
Support Science of Chess posts!
Thanks for reading! If you're enjoying these Science of Chess posts and would like to send a small donation my way ($1-$5), you can visit my Ko-fi page here: https://ko-fi.com/bjbalas - Never expected, but always appreciated!
References
Gobet, F., & Simon, H. A. (1996). Recall of rapidly presented random chess positions is a function of skill. Psychonomic Bulletin & Review, 3, 159–163.
Pfau, H. D., & Murphy, M. D. (1988). Role of verbal knowledge in chess skill. American Journal of Psychology, 101, 73–86.
Simon, H. A., & Chase, W. G. (1973). Skill in chess. American Psychologist, 61, 394–403.
van der Maas, H. L., & Wagenmakers, E. J. (2005). A psychometric analysis of chess expertise. The American journal of psychology, 118(1), 29–60.
Vicente, K. J., & de Groot, A. D. (1990). The memory recall paradigm: Straightening out the historical record. American Psychologist, 45, 285–287.
You may also like
 NDpatzer
NDpatzerScience of Chess: What does it mean to have a "chess personality?"
What kind of player are you? How do we tell? danbock
danbock11 things I did to take my USCF rating from 1547 to 1976
I’ve had some ups and down in the year since my first blog post, where I wrote about what was workin… GM Avetik_ChessMood
GM Avetik_ChessMoodThe bold-unbold technique: no more forgetting what you learn
Do you have challenges with memorizing what you’ve learned? You’ll love today’s article! CM HGabor
CM HGaborHow titled players lie to you
This post is a word of warning for the average club player. As the chess world is becoming increasin… NDpatzer
NDpatzerScience of Chess (kinda?): Viih_Sou's 2. Ra3 and a modest research proposal
Take the 2. Ra3 Challenge! For Science! NDpatzer
NDpatzer