
Heuristics, mnemonics, hard facts and lots of updates.
The ratings go BRRRRRRRRR! Since my last update of introducing timed play I have been diligently working to improve my engine and it has payed off massively.Intro
I came into coding the engine with no prior knowledge at all. I had a vague understanding that an engine generates legal moves and then looks at millions of them to find the best move. I always assumed they were cold dumb number crunching machines. Then I started researching their algorithms. At first many of them did not make any sense then, more often than not, I realized that those algorithms actually mimic human behavior and thought process. It just appears bizarre to realize how some of our mnemonics and heuristic thinking looks when formalized in terms of code.
A heuristic is a logical short cut - instead of using hard precise logical arguments we use a heuristic as a reasonable substitute. An example would be "pawn takes queen is a good move". It most certainly is in most cases unless there is a better move that leads to mate, prevention of mate or even more material gain. When we see a pawn takes queen move we instantly register it as a good potential move and then check if it really is.
A mnemonic in this context is a more abstract pattern of thinking. The best example would be the concept of threat in chess. How would you describe what a threat is to someone who has no understanding of the concept? A threat is a move that if given another move without response of the opposition would lead to a serious advantage. Again during our chess games we quickly notice these threats - we unconsciously make two moves in a row when we spot a threat.
Heuristics and mnemonics are so natural to human thinking that we rarely introspect on them. However, in my journey of chess programming I have come across them so many times and every time I see them they look outlandish until you deconstruct them and realize that they are already second nature to you.
Updates
Since the last post I have almost re-written all of the code of my chess engine. Part of it was aesthetics and part performance and as it turned out just cleaning up the code also came with some performance gains. So the list of updates will be a lengthy one.

Making friends
JUST IN: In the time I was writing this blog my bot managed to score its first win against its arch nemesis @zeekat
The total result against @zeekat now stands at +1-28=2 (1 win 28 losses 2 draws)
But ever since it's been online it has found friends and played a lot of fun matches. In other words - all the bots on lichess have beaten me up for my lunch money and stuffed me into the hallway locker after class.
Perft
Which is short for performance test. It is so much more than just a performance test. The perft function simply makes all legal moves in a position and then makes all legal responses and keeps doing it until a given depth. On the first move white has 20 legal moves- single and double moves for all eight pawns and four knight jumps. The same applies for black. So after both sides have played their first move it is possible to have 400 different positions on the board. What about white's second move? This is much harder to come by - white could have moved a pawn on the first move to open up the queen, bishop or even rook. Or white could have blocked a pawn with their knight... The number of positions after white's second move is not trivial to compute.
However the answer is 8,902, no less no more. I found this and many other numbers online where chess engines have calculated the number of positions at various depths. Why is this useful to know? Well it is a health check on your engine - generate and count all the moves and compare this value against the consensus. If the numbers add up all is good. If not you got some bug fixing to do.
Also it measures the performance of your move generation. Engines are not the best at picking out good moves in a position. So they compensate by looking at a lot of them. So the faster you can generate legal moves the more moves it can look at and play better. The perft program I wrote is an excellent assistant. I can freely experiment with optimizing some functionality then run the test and see both - did it help the performance and does it still generate the same moves.
Treeless tree search.
In a previous blog I laid down the fundamentals of tree search. Which is still relevant in all engines in some variations. My most natural approach of putting it into code was exactly that. Create a tree object and then traverse down while expanding it with new nodes. The number of nodes increases exponentially at depth and many if not most are not ever visited. Constructing the tree in memory was extremely memory inefficient to the point where looking too deep or playing too many games at once would crash my program as it ran out of memory.
How do human players explore variations? They look at the same board (or ceiling in Naka's case) and imagine moves being played. To explore a different side line you unwind the position a bit - take some moves back - and play out different moves. You do not construct an entirely new board for each option and then keep a bunch of them in your memory.
This is exactly what I did with my program. I can now make moves on the same board and take them back. Trying all the different positions in the game tree but with never actually constructing the tree. It just remembers what moves had been made and how to unmake them. Unmaking a move is not trivial as just moving the piece back. You have to remember many different details. Do I need to put a piece back on the board if my move was a capture? Do I need to restore my castling rights or ability to capture en passant? It certainly has it's challenges but the change to treeless prevented crashes where I ran out of memory and now it never consumes more than a few megabytes which is less than 1% of the memory available.
Quiescence search.
Again I will need to refer back to my previous blog post where we talked about the alpha-beta pruning algorithm. When searching at a given depth we always have a horizon effect- the depth has reached it's limit and we can not see past it. This is unavoidable. One can increase the efficiency of their program to see further but each next step is ever so more expensive where we hit a limit.
When the maximum depth is reached we evaluate the position without taking any more moves into consideration. This is our evaluation function. It will count up all the material and the quality of it. Assess king safety and other principles. This is all great. At the final depth your queen won a pawn and it evaluates the position- counts the material and gives you a +1. You're a pawn up good for you. Just for the sake of it let us look just one move deeper. Oh no MY QUEEN! (actually). It turns out on the very next move the opponent can just take your queen and from being a pawn up you end up a queen down. We could have never known about this because our initial search stopped before we could see the disaster. Of course this never really happens. If on your turn you computed the line 4ply deep on the next move you will already see that the line doesn't quite work as the initial queen loss is now no longer beyond the horizon and the algorithm will certainly deviate from that path. Maybe by losing the queen a completely new and novel way.
I saw this happening by looking at the console of my program where it logged some intermediate data of the search for each depth and with every new depth the evaluation would change drastically like: +5, -2, +4.8, -1.4.... That indicates that at each of those steps something was probably captured and many other pieces were probably hanging. Absolute nonsense.
The problem is clear - it is inappropriate to make a static evaluation in a position where pieces can be captured. The solution is quiescence search. After the initial search has reached its maximum depth and where we would normally return the static evaluation it starts a new one but this time with no depth limit but only considering capture moves. This will resolve any tension left in the position and condense the final position to a quiet one. The no depth limit sounds scary but since we are looking at only captures the number of moves is not that great and making a few exchanges we can quickly see if it good or not.
This change is the most substantial improvement together with changing from the basic minmax to alpha-beta pruning in terms of it's play strength. I was quite surprised that not only it did no longer engage in tactical lines where it would end up losing material, the evaluations became so much more consistent and accurate.
Here's a game before the quiescence search. Notice all the belligerent queen moves - threaten something, get pushed away, threaten something else... Like a chicken without a head.
Contrast this to a more recent game. There is so much more rhyme and reasoning to the play. It still is very aggressive but not to the point where it constantly loses tempi on every move in the opening.
Without having changed anything at all about it's understanding of positions it in one moment learnt to play chess. I wish someone could just tell me - 'Don't hang your pieces' and that would have a tremendous impact on my play.
What's to come?
PVS
Principal Variation Search. I still need to do some research and clean some things up to implement it. The idea is an improvement of the currently used alphabeta search. It is used together with iterative deepening. It uses the best variation found in a lower search and assumes it is still the best. It first searches the moves in the Principal Variation and then verifies that no other variation is better. If it does so the search is very fast. If it fails it has to do some re-searching from the point of divergence.
Profiling
Having rewritten the whole code from scratch and eliminated the obvious dumb things and with a handy perft at my side, I am putting a lot of my code under more scrutiny. I have started to use a profiler to see how the program behaves when it is running. Where it spends the most time and memory. For example, in my move ordering I checked if a move came with check or even double check - usually good moves. However, the time it took to verify it is a check actually was too expensive and did not provide the necessary benefits from additional pruning. So I removed it and the performance increased by ~15%. I will be using this technique to find little edges and improvements where I can.
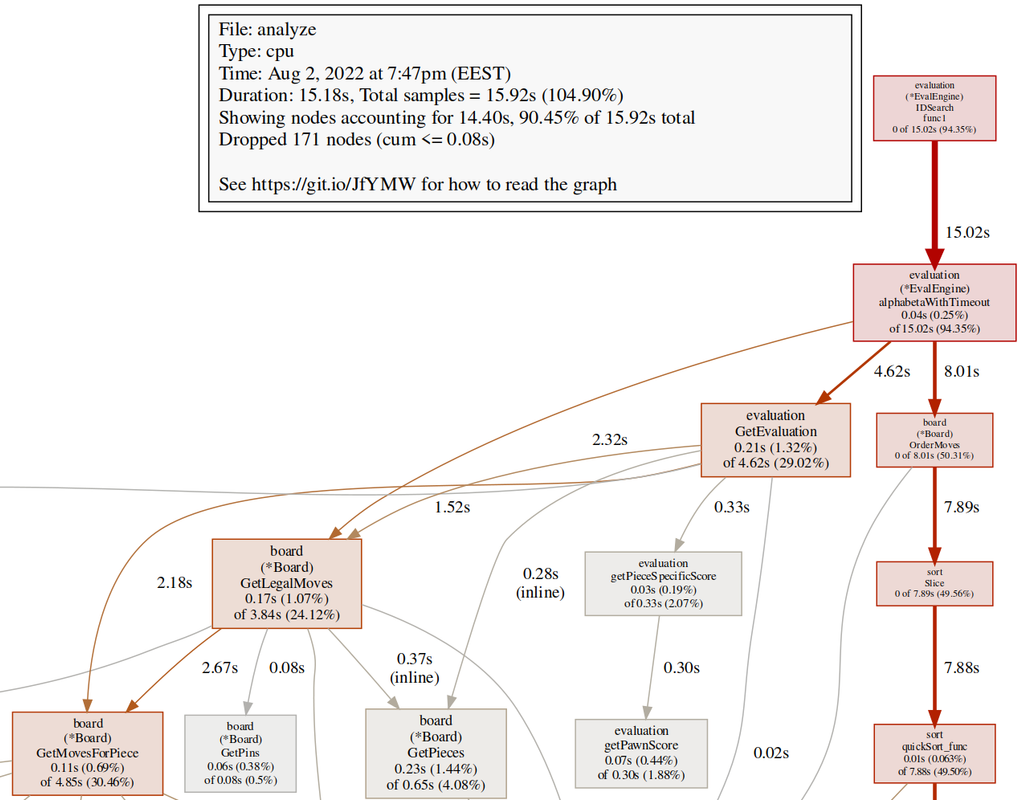
The profiler breaks down and displays the time spent in various parts of the program. The bigger, redder and bolder the more time is spent there and those are the prime areas of optimization.
Transposition tables
A transposition in chess is reaching the same position but by a different order of moves. Transposition tables store values from a search. If a position repeats in our search we should not have to do it all over but use the result obtained earlier. I have experimented with this a bit and got mixed results. In the early middle game where the positions are rich and I am unable to reach greater depths transposition tables slightly reduced the performance. However, in the endgame with few pieces and them moving back and forth and searches becoming deeper. Transpositions occur more often and are very beneficial. However, I noticed some strange behavior here and there and am currently not using them.
Evaluation & Black-box optimization
I added a few lines of code to evaluate pawn structures. I penalize doubled and isolated pawns and I add more score to protected, passed, center and advanced pawns, which seems to benefit the strength. Bad pawns often don't immediately result in loss of material but they can contribute to pieces being tied down to protect them or create long term weaknesses. Since my engine can only search very shallow it needs extra encouragement to avoid these long term disadvantages.
From the games it plays it would also probably benefit from rooks being valued more when connected and/or on open & semi open files.
There is no concept of king safety nor activity. This I hope to achieve with a tapered evaluation approach. Have evaluation for king safety and activity but weight them according to the game phase. Favoring safety in the opening and as the game progresses towards the endgame the activity evaluation would gain higher bias in the total.
All the values I have assigned to all these concepts are purely my guess and adjusted a few times by analyzing its play. The risk with making it a very accurate evaluation of the position is the cost that comes with it. The more detailed the evaluation is the more computational time is taken away from searching positions.
I tried to use a black-box optimization approach to find more optimal values for my weights. The idea is simple. I pass all the weights as parameters to a function that plays my engine against stockfish and after a certain number of moves stockfish gives the evaluation of the position. The optimization comes from changing all the weights to achieve a more favorable evaluation from stockfish. It seems like an interesting approach and I will revisit it in the future.
In conclusion
There is still much I could write about what has been done so far and what can and needs to be done in the future. At this point, however, I feel more like doing those things instead of talking about. I am super excited about the few huge jumps in its playing strength that it motivates me to keep pushing.
Finally I will leave you with this small gem of a game.
A beautiful tactical exchange where my boy ends up sacrificing the queen for two minor pieces a rook and a pawn and a busted enemy king position. The conversion went pretty smooth after that.
More blog posts by likeawizard

Tofiks 1.3.0. is looking good!
New looks, new home, new friends and even more motivation to push forward!
Tofiks 1.2.0
A new release and not even a year has passed? I am truly spoiling my chess playing dog.
The highly frustrating side of chess engine development.
While chess programming has been my top hobby and passion over the last two years. At times it comes…