
The highly frustrating side of chess engine development.
While chess programming has been my top hobby and passion over the last two years. At times it comes with a lot of frustration and fruitless efforts.Introduction
First of all, I want to give a huge thanks for everyone who read my last blog. It had the biggest reach of all of them so far. Also the number of you who actually gave it a go and played against @likeawizard-bot was astounding. It really does mean a lot to Tofiks and me. It motivates me to work on it even more and I am eager to keep sharing my work and experience with you. Despite Tofiks being an inanimate dog-chess-playing-program I am sure deep down he feels the same.
It truly is a great hobby. It has helped me grow professionally. Seeing your creation evolve and outgrow your own playing strength and having some ambitions to reach even GM levels of play is a rewarding experience. The objective is always the same - make it play better chess. It's a good objective as no matter its current strength there is always some more to be extracted.
What makes a Chess Engine strong?
I always felt there is a great comparison to physics and Power which is can be described in the following way: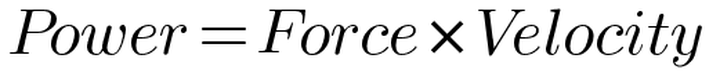
The more forceful and faster something is the more power it has. However, there is another aspect to the equation which I find more relevant. Something with less force moving faster can have the same power as something that moves slowly with great force. This is the part that translates to chess playing ability the best. So hopefully without too much controversy I can introduce a similar equation for chess: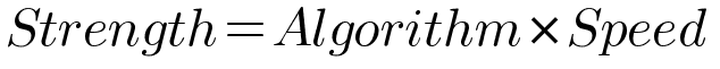
For an engine to play strong moves you need a solid algorithm and make sure the computation is done as efficiently as possible. Let us look at some examples how you can make changes to your engine to improve it.
Increase the speed
This is the raw efficiency of your code. I often use a profiler to analyze the CPU and memory usage of my program and try to make it more lean. A great deal of computation is required to generate all the legal or pseudo-legal moves in a position. You can look at my previous blog on the various Board Representations in chess. The choice and the implementation can have dramatic impact on your engine while it is still doing the same - producing the moves in a position. Faster move generation allows exploration of more positions and see further ahead and increase the strength. Essentially an increase in raw performance is doing the same thing just faster and more.
Improve the algorithm
Chess engines have hard-coded values and weights. These include the material values of all the pieces. As well as Piece-Square-Tables. These are values that indicate how good a square is for a particular piece. A knight on the rim is dim. Rooks are strong when they get on the second rank of the opponent. There are also weights to evaluate pawn structures - how much value does a pawn get/lose when it is connected, passed or doubled. Similarly other weights will be used to calculate king safety, piece activity etc... The choice of these values is tricky. You can use your intuition or analyze a large amount of games and determine these values more systematically. But the point I ultimately want to make - picking better values for all the weights will improve the evaluation and make your engine stronger at no additional cost - you're still reading the same weights they just happen to have better values.
Can you improve both at the same time?
No. Not unless you had been doing something extra ordinarily stupid before. Like wasting a lot of computation power on things that make the algorithm objectively worse. The reality is that in most cases one comes at the cost of the other.
Algorithm vs Speed
To improve your algorithm you usually need to write more code. Code does some computation and that takes CPU time and memory. It is guaranteed to come at some cost of performance. So really when introducing a new feature you need to think whether it will improve the algorithm enough to offset the decreased performance. A great example is Stockfish introducing NNUE. They improved their evaluation at the cost of speed. Using NNUE pushes down the nodes per second examined by Stockfish but the trade-off has been totally worth since the NNUE version is clearly superior.
What if the trade-off is not worth it? For example early on in my development I realized how important move ordering is. If you search the best moves first you can massively decrease the number of nodes needed to be searched because of alpha-beta pruning. So naively with my chess knowledge I though okay - checks and captures are usually good moves and should be searched first. That is not wrong. Those are potentially good moves. The problem was that to determine if a move comes with a check requires considerable calculation. Since many positions do not have moves with checks in them at all and only few moves come with check when they exist - that added a huge computational overhead for every single move that was being generated. Even though they were good moves to search first the added complexity made the algorithm significantly slower and at some point I removed it and the playing strength increased significantly even though it was playing dumber.
There is another great example. Move generation. To generate legal moves you always need to ensure that you do not leave your king in check after the move. It is illegal. There are smart ways to handle pins and ensure that the legality of moves can be calculated as cheaply as possible. However, I learned that many if not most engines do not bother to generate legal moves. They generate pseudo-legal moves. Pieces still move according to their normal rules but there is no enforcement of not leaving your King in check. The legality of a move is only checked when it needs to be played - you play the move and if it is illegal you simply take it back and proceed to the next. That sounded bizarre to me at first. Because making sure all moves are legal is cheaper than generating all moves and then trying them out and making sure that it was legal after the fact and taking it back otherwise. Well... It turns out that during search with good move ordering it is often enough to only check a few moves before you can abandon that particular node. So by generating moves more cheaply and deferring the legality check to the point where it might not be necessary to be checked at all you gain some net performance. We made our move generator dumber and yet ended up with a net gain.
History Heuristic
This blog post is mostly inspired by my recent struggles with the implementation of the History Heuristic. The History Heuristic is a move ordering method. Whenever we find a good non-capture move (we ignore captures since they are already easy to order using MVV-LVA and other methods like SEE), we add it to a history of good moves in an abstract way. The history is defined by two keys (from, to) and has an integer value that we increase every time we find a good move between those two squares. The idea is to represent more abstract and strategic ideas in a position. It does not even matter what piece is moved or in what position was such a move good. It simply relies on the fact that if many moves like that ended up being good - there is a chance this one might too so try it before others. It made enough sense to me to try it out. The code was rather simple to write.
Then I tested it... I made Tofiks with the new history heuristic play against Tofiks without it to see what improvement it would give to the playing strength. The new version was being absolutely crushed. I had to double check and re-compiled and tried again. Crushed. I was looking for some obvious bugs. All seems in order. Still getting crushed. Okay let's try something different. Have one Tofiks that prioritizes moves with a higher history heuristic and the other that actively avoids them. This was a sanity check - maybe I messed something up so bad that it plays worse now. This time the proper History Heuristic version was crushing the version which did the ordering opposite to what the history heuristic suggests. Not even close. Way harder than it was crushed before.
What does this mean? It's obvious. Although the added algorithm made it play smarter it did incur a small performance hit. And the older and dumber version was at times able to see a bit further ahead due to raw performance. The improved ordering was not sufficient to cause significantly more pruning to offset the performance loss. So what now? Is it just a bad idea?
Can you improve both at the same time?
This was asked and answered but I believe there might be more to it. So my revised answer would be -Yes, I believe so! The History Heuristic is a good example for this. The initial test was a failure because of the added performance but it still did its job right. When we tested it against its own opposite that had the same performance overhead the results were there. Despite the history heuristic being able to detect potentially better moves it can also be reasonably assumed that when the history is gathered only over a limited number of moves the data is not there to predict good moves clearly and there might be a lot of trash outliers. Improving the performance would allow us to see more positions and more moves and build better data for the history. That would make the history heuristic scale better at performance. So there is a an added value of increased volume. The algorithm should become stronger when it sees more positions and gathers more significant data.
I spent several days on cutting corners. Optimizing code. Just to gain some performance so that the history heuristic version would become viable. I made sure that certain often used values are pre-computed and reused. That sorting moves according to their scores is done as efficiently as can.
With all the performance improvements that were made to justify the newly added feature would it be possible that removing the heuristic now would be still an improvement? If so would even more raw performance at some point turn the curve where removing the history heuristic would decrease playing strength?
Those are really the hardest questions to answer and sometimes parts of the engine become so interlinked and might have ripple effects affecting other parts indirectly. It requires a lot of testing via self-play, analysis of hard metrics. What makes it even more opaque at times is that different features benefit different types of positions. Some might help with performance in highly tactical positions, some in quiet strategic ones and others might help find a checkmate as fast as possible. Given that in a singe search many millions of positions are examined it is very hard to debug such code in a classic way with breakpoints. You just need to test it by playing enough games where you can see a statistically significant improvement.
Conclusions
It is often that the way towards improvement is not clear at all when developing an engine. It requires a lot of trial and error. Good discipline in testing and isolating features to see what impact they bring. It is in very stark contrast with software development that I am accustomed with where I have a problem in front of me that needs a solution. The acceptance criteria is clear. You can strive to implement it the best way possible and it will be good enough even when it is not that good. As long as it works it can always be improved or fixed. In chess there still is a margin for good enough, but that margin often is razor thin and when you land on the wrong side of it, it is no longer acceptable as you have taken some steps forward some back and ended up with a net negative.
So the process can be very tedious and is not linear at all. The end result when you get it right is always worth it.
Having just released Tofiks v1.1.0, I will take a bit of a break from active development for a short time. Currently I am working on another related project. PolyGlot Composer it is a CLI tool to compose opening books from PGN game collections. It reads the games and filters out low rated or bullet games and builds a opening book from those. The current version of Tofiks is playing of a book composed with this tool. It scanned through 4 month worth of games of Lichess 20 plys deep and the result is a book of ~200Mb. I want to dig deeper and expand the the depth to 40plys, but that would make the book huge. So I would also need to curate some of it. To make sure that there are not a lot of bad branches. I also want to make it more stable as the time to download the games from Lichess can take many hours and if a crash occurs you have to start over again. I am currently working on a feature that would allow it to resume the progress.
And again - thank you for reading and taking your time to play against Tofiks on @likeawizard-bot. I hope this blog and the games you play can give you just a fraction of joy that I get out f it.
You may also like
 GM GABUZYAN_CHESSMOOD
GM GABUZYAN_CHESSMOODWeak Squares in Chess: Everything you need to know!
Getting better at exploiting weak squares improves your ability to win equal-looking positions. This… likeawizard
likeawizardReview of different board representations in computer chess.
Over the months of coding my engine I have gone through several implementations of the way the board… likeawizard
likeawizardThe importance of caching in chess engines
My chess engine development has been on a small hiatus lately but I am by no means finished. There i… IM datajunkie
IM datajunkie#29: The 14 Rules of Hedgehog Club
Welcome to Hedgehog Club. The first rule of Hedgehog Club is: you do not talk about Hedgehog Club. GM NoelStuder
GM NoelStuderWhy Losing At Chess Hurts So Much (And The Antidote)
Losing a chess game hurts. It certainly hurt me a lot in my professional days. Sometimes I needed da… GM NoelStuder
GM NoelStuder