
Announcing the Personal Opening Explorer
Indexing RandomMoverBot ...
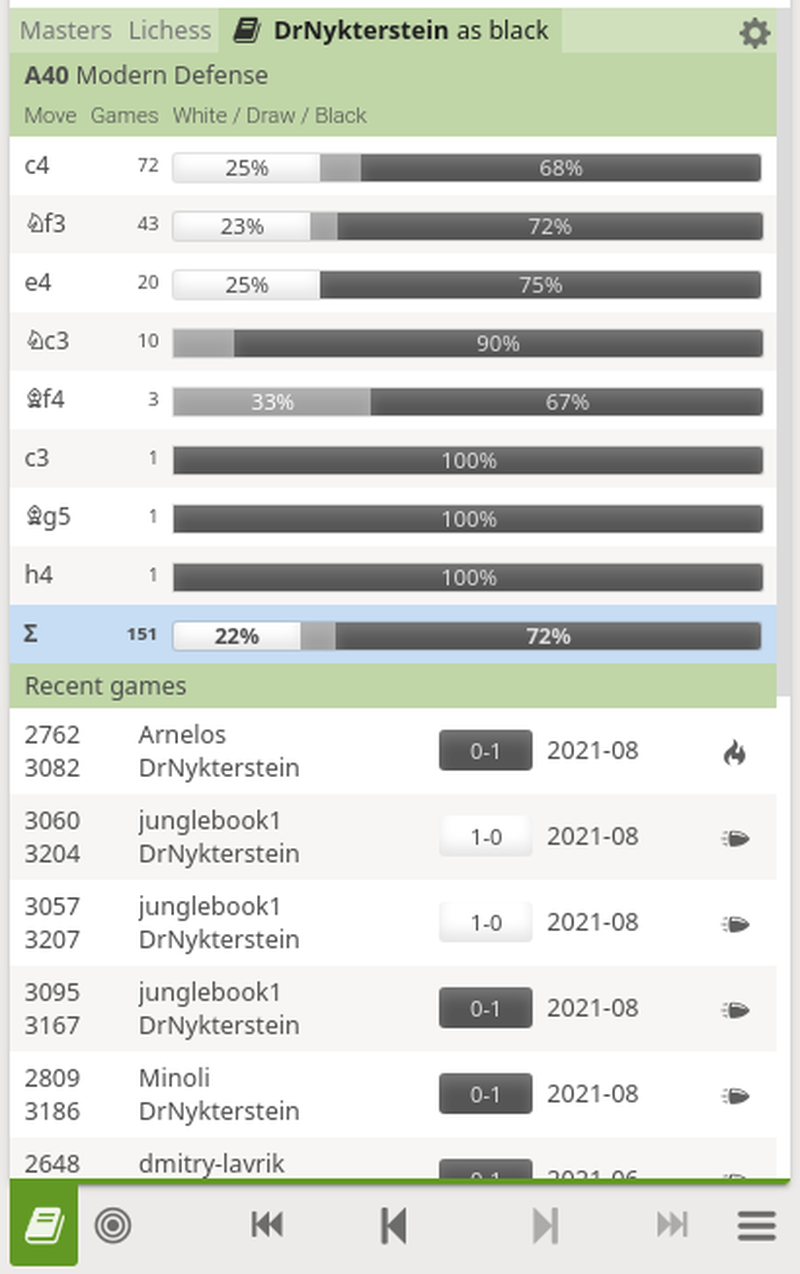
We're pleased to announce the general release of the new personal opening explorer. It has long been one of the most popular feature requests - and for good reason: being able to investigate your personal strengths and weaknesses in various lines and openings is really useful for learning! Through the analysis board you can now see your win/draw/loss statistics for the moves played in any position - as well as easily compare your choices to the rest of the Lichess user base, and our Masters database, through the tabs. The personal explorer is filterable by time control, rated/casual, and date range.
You can also choose the personal explorer of any other Lichess user, through the cog menu, so you can see what lines your favourite players choose, or prepare against an upcoming opponent.
It's worthy of mention at this point that these features have been available for a while on OpeningTree.com, by making use of the APIs to get Lichess game data. That site has been a fantastic excuse for us not to implement the feature natively for a long time, because it did the job so well - and is a great example of the power of the open source community. It also offers some functionality that isn't in our update like filtering by tournament, opponent, and opponent rating - so to those hardcore opening fans, do still check it out.
We hope you enjoy the new tool, let us know in the forum what interesting findings you discover!
If you'd like to know more about the technical implementation details please see the following section.
Technical details
To implement the personal opening explorer, we chose an approach very similar to the existing explorer. It is essentially a huge key-value database with denormalized information.
This time, games are indexed on demand, by streaming them from our public API. The opening explorer in turn, implemented in Rust using axum, can stream statistics for the user games that have been indexed thus far.
We chose RocksDB instead of Kyotocabinet (which is still used in the main opening explorer, at least for the time being). It is more complex, but a few of its more advanced features turned out to be extremely useful. The first one is simply transactions across column families, so that the indexing status of a game and the stats for each position are always consistent.
Keys of the primary column family start with a 12 byte hash for the position, side and player, followed by 2 bytes for the month. We let RocksDB know that we will never need to iterate across the 12 byte prefixes, but that we do intend to iterate over months chronologically/lexicographically, to answer queries for date ranges.

The prefixes are randomly distributed, but RocksDB transforms random writes into sequential writes plus occasional compaction runs.
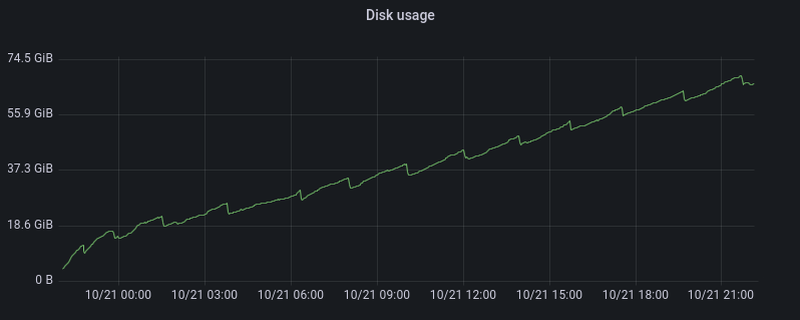
Disk usage during the first day of beta testing, with clearly visible compaction runs.
Each entry then stores aggregated stats for all moves that have been played in the position, as well as a limited number of references to recent games.
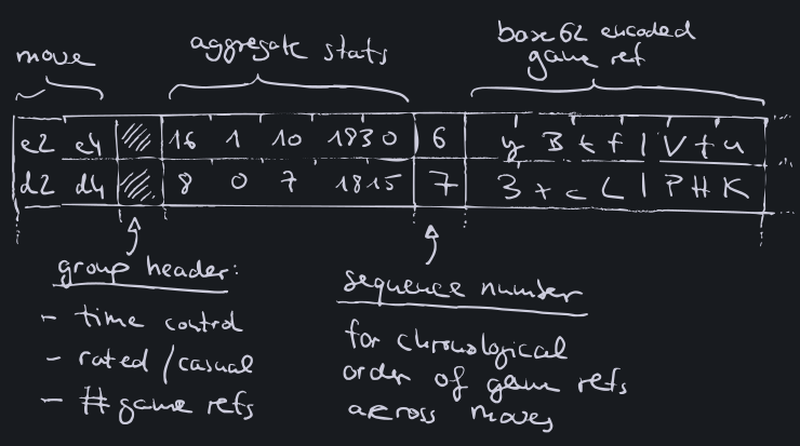
There are two constructors for entries, and an associative merge operator. One constructor for empty entries, one constructor to create fresh single-game entries during indexing, and of course the merge operator to combine existing and incoming entries.
The associative merge operator can be registered with RocksDB, so that a transaction to read/combine/write can be replaced by a merge operation.
The same merge operator can also be used to aggregate the answer to a query, when iterating over all entries in the selected date range.
Just like all of Lichess, the software is free and open source.
More blog posts by Lichess

Candidates Round 12: Three-ways Tie in Open, Tan Maintains her Lead
Nakamura and Gukesh catch up with Nepomniachtchi in Open, while Tan maintains a safe distance from e…
Candidates Round 11: Nepomniachtchi, Tan Back in Sole Lead
Nepomniachtchi and Tan lead alone once again, while Nakamura's win puts him in shared 2nd with Gukesh
Candidates Round 10: Nakamura and Caruana Bounce Back, Lei in Shared Lead
Nakamura and Caruana bounced back with wins against Abasov and Firouzja, respectively, while Lei bea…