Adapting nnue-pytorch's binary position format for Lichess
Lichess stores lots of chess positions, and (thanks to Stockfish) now more efficiently
Games on Lichess are stored as sequences of compressed moves. In some other contexts its technically required or convenient to directly store positions. Thus far we were using FEN
6k1/7p/6r1/8/8/8/7P/5BRK b - - 0 1
or a similar custom (but still human readable) format with reduced syntactic sugar:
6k17p6r18887P5BRKb
The requirements for a successor format are:
- Stores the same information as FEN: A description of a chess position, including piece positions, turn, castling rights, en passant square, optional move counters, but ignoring the move history for three-fold repetitions
- Supports all of Lichess's variants
- Actually, just support illegal positions, too
- Easily reversible (unlike the hash keys of the opening explorer, variable length is acceptable)
- Reading/writing not slower than FEN
Now to design a compact binary format for this ...
Turns out that Stockfish developers also have to store lots of positions as training data for neural networks. Thanks to free open-source software we can have a look and adapt it to our needs.
The format
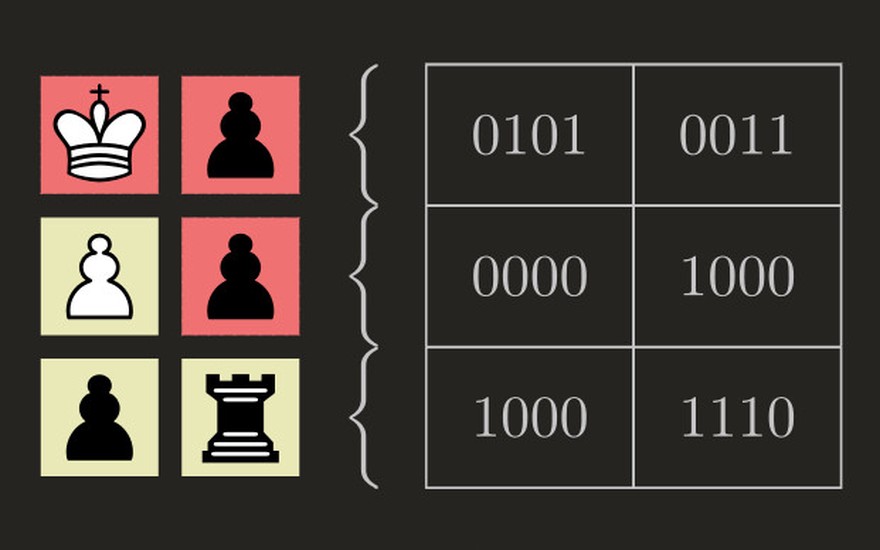
The format is simple and good. The first 64 bits encode which squares are occupied. Often, most will be empty, so it's useful to get those out of the way first.
The occupancy mask is followed by a sequence of encoded pieces, in the order at which they are to be placed on each occupied square. Half a byte (a nibble) is more than enough to encode the 6 possible piece types of each color. By sticking to nibbles we can work byte by byte, encoding/decoding two pieces at a time.
The 4 bits of a nibble would allow encoding 16 kinds of pieces, but we only have 12. So there's space to add 4 more special piece types:
- A white rook that can still participate in castling
- A black rook that can still participate in castling
- A black king with the additional information that it's black to move
- A pawn that has just been moved two squares and can be captured en passant (we don't have space for a distinct piece type for each color, but the position of the pawn is enough to infer this)
That's the original format, and sufficient for every legal position.
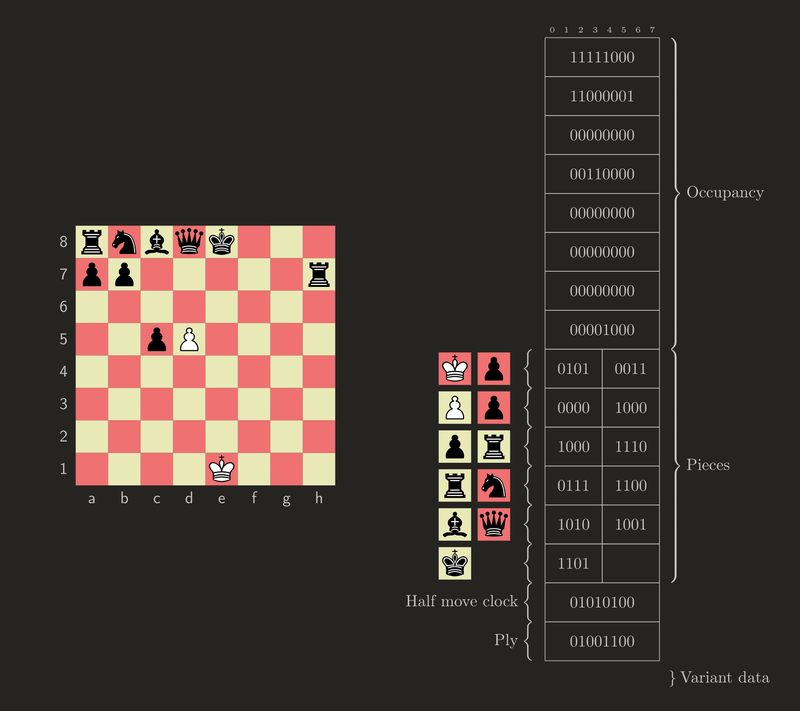
Some small tweaks are needed to adapt it to our requirements.
If required in the current context and not default, we tack on LEB128-encoded move counters (half moves since the last pawn move or capture, and full moves plies since the start of the game). In most cases that will be 1 byte each.
If not standard, we also tack on variant data (variant identifier, Three-check counters, Crazyhouse pockets and promoted piece mask).
That leaves one final problem: We are using the special black king to encode the side to move, but Antichess positions, Atomic positions after nuclear Armageddon, or downright illegal positions may not have one. Note how earlier we sacrificed a bit by appending a ply counter instead of a full move counter! So all that's left to do, is making the move counters mandatory in this case.
Space savings
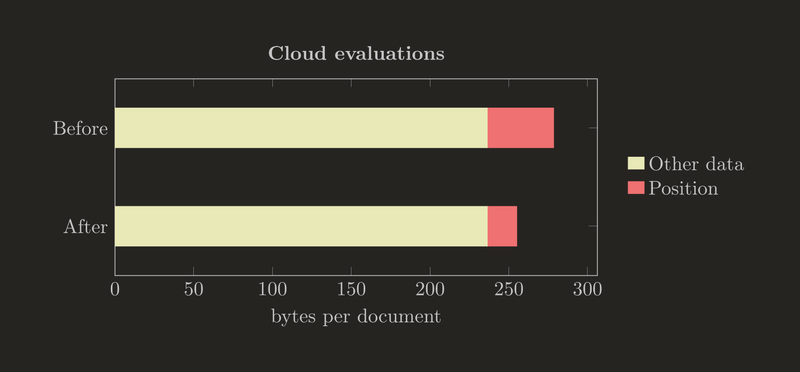
As of this week, we're using the format for cloud evaluation storage. The average syntax-sugar-less FEN here was 42.1 characters long, and is now encoded in 18.7 bytes, for 56% savings. Viewed next to the other data stored in the cloud evaluation collection (based on MongoDB's avgObjSize) it looks less impressive, but it's a good way to test-drive the new format and ultimately required to retire the previous one.
The average study chapter carries 10927 bytes of position data, for which a 63% reduction down to 4054 bytes is expected. Here the savings are significant, even viewed next to the remaining data.
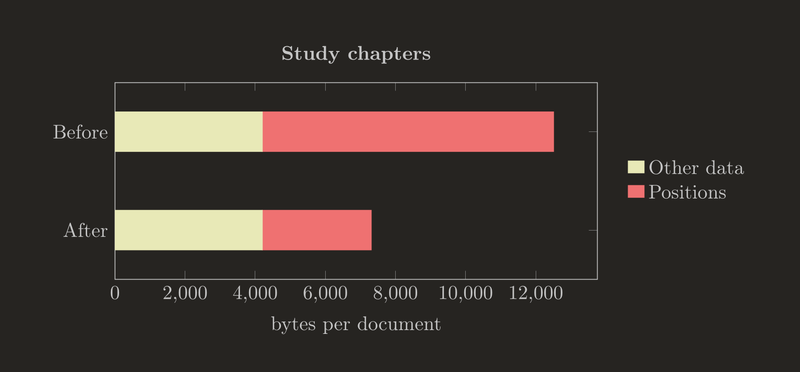
The document sizes here are before general purpose Zstandard compression (which is expected to reduce but not eliminate the impact).
Performance ballpark
Byte-aligned encoding/decoding leaves a few bits on the table here and there (not even beginning to consider entropy coding as used for our game compression), but makes it easier to create a decently fast implementation.
Thanks to the recent work on the foundations of scalachess, it's also no longer a performance compromise to implement formats like this directly in the library.
In primitive benchmarks, reading and writing appear to be roughly 50x faster than scalachess's FEN parser (certainly not slower, which was the goal).
The next step after carefully watching the cloud evaluation storage for a while will be to migrate the study chapter collection.
