
Time Control Support Is Here!
I will keep this pretty short but I am very excited to announce that play with time control is now available in first testing stage.Introducing Real-time play. Finally!
This is a huge milestone and I am very excited for things to come. Why did it take so long to introduce timed play? Well the biggest blocker was my failure with minmax and alphabeta pruning algorithms and the bug in the code prevented me from playing at any real speed without the engine not being completely brain-dead.
Challenge it to any game with live time-controls and have fun: https://lichess.org/@/likeawizard-bot
Before we go on let me have a small note on things that have been fixed and top priority tasks:
- Play with clock is now available. Bullet, Blitz, Rapid, Classical. Increment or no increment. I currently filter no challenges apart from correspondence/unlimited, which are currently disabled.
- There are still a lot of challenges with proper time allocation for every move. The current live version is mostly so I can fine tune the strategy.
- It still sometimes gets flagged against stockfish. It might be poor time management or it might be a lack of lag compensation or some internal overhead where time is lost.
- For simplicity until now my engine always auto-promoted pawns to a Queen. This causes issues as it can no longer properly understand when lichess sends a move with promotion. So promotion moves on either side just kill the engine outright.
- I still haven't had the time to fix issues where it would stalemate an opponent in a winning position.
- There is no proper recognition of threefold repetition or 50-move rules. So the engine might draw a winning game by threefold repetition.
- I am getting more and more frustrated with the evaluation function. I observed quite a few games against friends, lichess users and self-play: It has no interest in castling or other wholesome activities.
- Allow pondering on the next move during the opponents turn. It improves the performance when looking at my own moves after it has spent some time thinking during the opponents turn but it seems to crash the engine probably due to a memory leak bug.
Iterative deepening - the key to real time play
This section heavily relies on the understanding of the last blog entry of alpha-beta pruning. So to fully appreciate I would recommend reading my last blog entry first. The short version is - alpha-beta pruning allows the same safe and reliable search of minmax but it has the potential to increase the performance of that algorithm significantly. If it explores the best variation first then it can quickly refute other variations with relative ease based on upper and lower bounds that would be unfavorable for one side or the other so those lines can not be reached and can be pruned.
So for alpha-beta to work best it is necessary to order the moves before they are searched. Ordering before a search involves a lot of guess work. That's actually quite hard.
There are several other issues with searching for a move with alpha-beta at a predefined depth.
- It's hard to exactly know how long it will take to search the tree at a given depth.
- The algorithm doesn't produce meaningful results before the whole search is finished.
- Searching at a depth of 6ply might be quite labor intensive in the opening or a rich middle game. But when the number of pieces start falling off and the branching factor (the number of legal moves in a position) of the game tree shrinks significantly it is possible to perform deeper searches at lower cost. So I often observed how my engine played a slow, reasonable middle game and in the endgame it started moving like a speed demon without any reason or purpose.
The answer to all those points is Iterative Deepening search. In it's most basic implementation, which also happens to be my current implementation, it simply performs the same alpha-beta search but starting at very shallow depths and after each search it produces a best move and also allows us to order the moves we just searched so the next search will will have some reasonable ordering already. It also allows us to 'cancel' the search at any moment and it will still be able to return the current best move. While in alpha-beta there is no current best move - it only makes sense once the full algorithm has run its course.
The current implementation is still lacking a lot of features that could really benefit the performance:
- It can be very beneficial to store the values of previously searched positions as they can often repeat themselves due to transposition - arriving at the same position but with a different order of moves.
- Cancelling a search at an arbitrary point in time can be extremely wasteful. Let's look at a simple illustration
Here is a small output from the iterative deepening search. It shows the best move it found at a depth. Total time spent and time spent at the last depth:
f3e5 at depth: 1 (time spent: total = 4.72ms at depth = 4.710ms)
h5f5 at depth: 2 (time spent: total = 23.59ms at depth = 18.841ms)
h5g5 at depth: 3 (time spent: total = 218.45ms at depth = 194.83ms)
h5e5 at depth: 4 (time spent: total = 1.40s at depth = 1.18s)
h5f5 at depth: 5 (time spent: total = 10.73s at depth = 9.33s)
If we had set the search time of our iterative process to 10s, we would have found the move h5e5 at depth 4 but if only we had been a tiny bit more patient we might have been rewarded with the possibly better find h5f5 at depth 5. Even worse - we just spent nearly 9 seconds searching at depth 5 and the only thing we have to show for our efforts is a move we found at depth 4 after only spending 1.4 seconds on the search. This is a very wasteful. This is also the problem I have in my program now. I will have to think how to solve this in the future.
One idea would to estimate the time it would take of the next search using some metrics as the search speed (which currently is quite slow in my implementation 10~13knps) and estimate the tree size for the next iteration. Another would of course be to improve the search speed to somewhat mitigate the lost search time- the move quality at depth 5 vs depth 4, I believe should is more significant than depth 20 vs depth 19. The deeper the search looks the smaller the chance of the move changing by jumping to the next depth. One could also try to see if the best move has changed at all over the last few levels of depth and just give up and save time for a more dynamic position in the future.
Time management.
How much time should you allocate for each move? Spend too much time in the early game and you will not have enough to convert the game and you throw it. Spend too little time in the early game and you will probably put on the best but ultimately futile defense in the late game.
Human players can often identify critical situations where it is worth spending more time. It can be after the opening- you have developed, castled and done all the 'obvious' stuff you need to do to step into the middle game. It is worth spending some time here to make sure you assess the situation correctly and come up with a solid plan for the middle game. Or in extreme tactical complications- your Queen is under attack and the opponent is also making other threats. There is no point saving time in a situation like this if you can't solve it. There is no difference if in the next few moves you run out of time or get mated. But if you manage to find some in-between move or some other brilliant defensive resource you might have a fighting chance later.
How do you explain this to a computer? I have no clue. One option might be to look deeper if the previous searches returned wildly different moves and evaluations- the engine has no clue what is going on so it should figure it out.
Currently I am employing a naive approach' "I expect the game to be decided by move X and I will make sure I have plenty of time until then, after that I expect the game to be converted either way". X depends in my current implementation on the time control- for longer games I expect less blunders. So I set X to 40 in longer games and for shorter games 30. I allocate my time for the first 'important' moves equally and then once I have reached the critical point of the game I assume that the game should already be decided and can be converted in the next 10 moves or so.
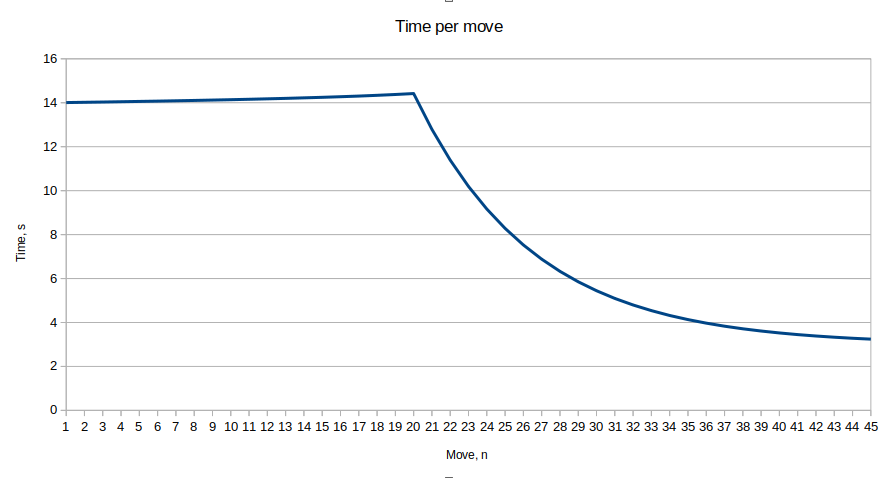
This would be a sample time distribution under 5+3 and the expectation for the game to be decided in the next 5 moves after.
This is a rather naive approach but it should suffice for some basic play. Before I extracted the formula from my code and plotted it I did not notice the small climb in move times until the critical move 25. This is simply an artifact from extra time I expect to lose from lag. If I have the lag compensation correctly estimated it should become flat again.
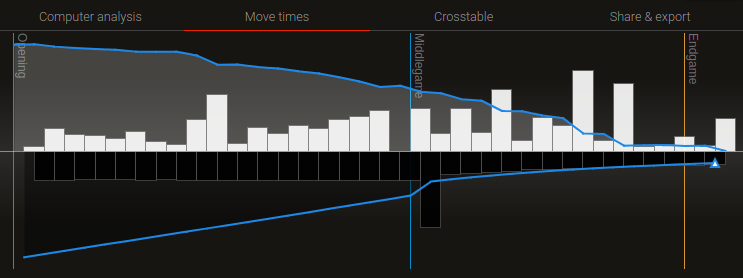
Black move times from a real game 3+2. With the target being move 20. Until move 20 every move is made in around 7 seconds and then there is a gradual decline that should asymptotic to the increment plus a bit of safety margin for lag. The singular spike I believe is a crash&restart mid-game.
What's next?
I will work on improving time management and also make smarter decisions on how to use that time- maybe give up faster in some searches or allocate some extra time for others. Spend zero time when only one legal move is present or speed up time when only one moves makes sense.
This, however, is right now what infuriates me most about its play:

Just castle for once you dumb @#$%!!!!
I have been running the engine either on self-play or on lichess and have been peeking at the the game and also the evaluation and what moves it considers. I saw the engine looking at moves at various depths and it's thinking process was- depth 1: do dumb shit with my queen, depth-2: do dumb shit with my queen, depth-3: do dumb shit with my queen, depth-4: castle, maybe?, depth-5: alrighty! do dumb shit with my queen it is!
For a moment there I was hopeful it had found some sense and I felt pride and started thinking of all the good things that might be. Only to have my hopes and soul crushed again with the same old Queen shenanigans.
So I think my focus in the near future will be to try improve the evaluation function so it would play more sensible openings. I will try to address king safety, piece development and placement and more advanced pawn structures. I have some ideas how to implement a smart evaluation yet take as much shortcuts to keep it simple.
Before we part I want to share this small little gem it played today. It found a beautiful smothered mate and my friend decided to resign before it could play out on the board. Bit rude tbh.
You may also like
 likeawizard
likeawizardTofiks v1.1.0
It's been a while since v1.0.0 but we got there and we will keep going. After all a good dog require… likeawizard
likeawizardReview of different board representations in computer chess.
Over the months of coding my engine I have gone through several implementations of the way the board… likeawizard
likeawizardThe importance of caching in chess engines
My chess engine development has been on a small hiatus lately but I am by no means finished. There i… likeawizard
likeawizardThe highly frustrating side of chess engine development.
While chess programming has been my top hobby and passion over the last two years. At times it comes… FM CheckRaiseMate
FM CheckRaiseMateEntropy in the Opening
Using information theory to quantify the surprise value of chess openings likeawizard
likeawizard