
Cover of The Rating Revolution, by Vlad Ghita
Why chess ratings don't mean what they used to

This article summarizes the core findings from my new book, The Rating Revolution. The full download, with a foreword by GM Levon Aronian, is available now.
Free preview available inside
Get the book — vladchess.com/rating-revolution
A relatable scenario
Start with a familiar feeling. You are 1900. Pairings give you a 1500 junior. You play carefully, equalize after every complication, and split the point. Over the board, it feels like a “correct” draw against an equal practical opponent. On the rating sheet, it is a penalty of -8.4 Elo points. You did not blunder, but your number still drops.
That experience is no longer rare noise. It is a repeatable pattern in the modern FIDE pool. For decades, Elo assumptions held well enough. In today’s environment, those assumptions are under scrutiny.
In some events, the Elo ratings of the players themselves become worse predictors of observed results than their federation. Think about the implications for a second. If a 1900 is not a 1900 everywhere, there is systemic rating arbitrage pushing some players down and lifting others up. In a modern rating system, this scenario sits at odds with a unified global standard that Elo is supposed to represent.
Elo’s original promise
When FIDE adopted Prof. Arpad Elo’s system in 1970, chess ratings served an exclusive club. The inaugural 1971 list contained just 592 players, all rated above 2200, topped by Bobby Fischer (2760). The governing assumption was simple. Only serious, skilled competitors would pursue FIDE ratings. This selectivity defined the system’s design. Elo was calibrated for a homogeneous elite in a mostly closed pool. It assumed a 2300-rated player represented roughly the same strength regardless of location.
As the rating floor fell to accommodate demographic expansion, the system underwent a fundamental transformation. It shifted from a static adult pool to a turbulent youth ecosystem. Modern chess now operates at velocities incompatible with Elo’s original assumptions about population stability. By December 2025, the list grew to 528,064 players—three orders of magnitude larger than its inception. Chess shifted from an exclusive club to a mass-scale system. Yet we still operate under parameters designed for the 1970s.
I have made this point multiple times in previous blog entries here on Lichess, but according to my knowledge, this is the first deep-dive into the data that focuses specifically on these geographic discrepancies and proposes a repair system.
The hidden deflation tax
In practice, deflation breeds in isolated federations where few players mix with international opponents. Think of it this way. When players from the same federation face each other, the only information we receive about their skill is relative to their own domestic pool. It takes a lot of cross-border play to recalibrate that signal. Until then, mismatches accumulate. Those mismatches have a measurable cost, which I call the deflation tax.
Undervalued entrants extract rating points mechanically from the rest of the global pool. Post-pandemic freezes amplified this taxation effect. The transfer became disproportionately large relative to pre-pandemic baselines. Unlike a fiscal authority collecting tax, these points move directly from established players to underrated newcomers. Mispricing corrects through play, but the burden falls on established players.
Remember the example at the beginning, but this time let's attribute federations to them. A Spanish 1900 faces an Indian junior listed at 1500, but playing near 1900 strength. Pairings like these are common in major open events (look no further than Sunway Sitges, for example)
1. The Elo formula observes a 400-point gap and expects the 1900 to score 92%.
2. The players are of equal strength; in reality, the adult scores 50%.
3. The adult performs according to their real strength (drawing an equal player), but loses 8.4 rating points because they failed to meet the Elo formula's expectation.
That gap between expected score and actual score is the adjustment cost. Repeat that pattern across many games and the pressure concentrates on rating favorites. In a purely theoretical model, a worst-case scenario of facing lots of these extremely underpriced opponents can yield cumulative Elo losses on the order of several hundred points. What does this mean for players? Having the “unlucky draw” multiple times in open tournaments can generate repeated Elo losses. The FIDE rating compression in 2024 reduced the magnitude of single-game adjustments, but the mechanism remained intact.
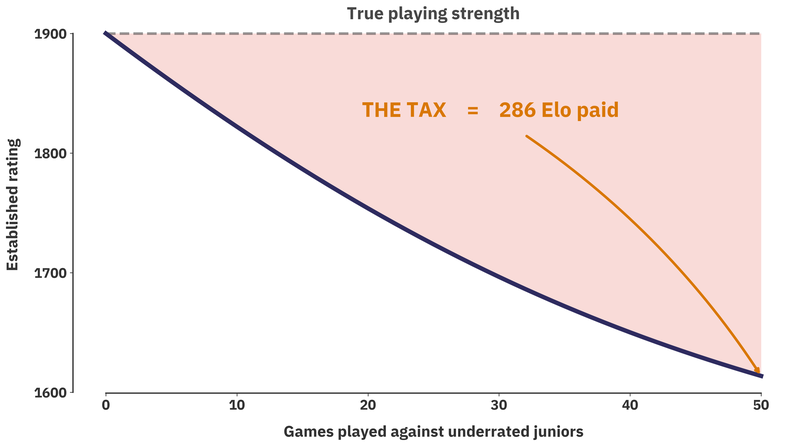
Of course, this represents a purely theoretical simulation. It's unlikely that someone has faced 50 underrated juniors by 400 points in quick succession. If that is the case, my sincere condolences for your rating. However, it's not that unlikely that you've faced more than 10 of these over the past 5 years, if you are an active OTB player.
So, let's recap. New players enter the system at whichever baseline their country is currently calibrated at. They translate the rating pressure to the rest of the global pool when they start mixing with international opponents. If the ratings at home are higher compared to the global baseline, it's likely that they become exporters of Elo. If the ratings at home are lower, they become importers of Elo to settle this debt between published rating and true strength.
If you personally lost rating in these mismatches, you’re not being punished for bad play. You’re paying off rating debt someone else accumulated. But is this theoretical... or does it actually show up in the data?
Rating changes by age cohort
Debt does not clear quickly. Ratings trail skill, especially for rapid improvers. If correction happened within a few games, the damage would stay contained. In practice, lag persists for long periods, which made the post-pandemic distortion much worse. Many juniors who trained at home during the lockdown were undervalued by a few hundred points once they resumed tournament play. Their opponents paid the deflation tax and subsidized their rating corrections.
When we look at the evolution of ratings across age cohorts, the tax payers split cleanly from the tax collectors.
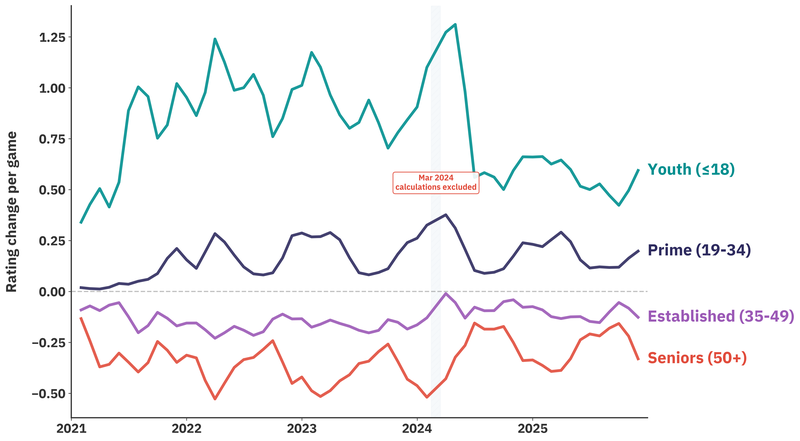
Players under 18 show clear rating gains. The March 2024 reforms partially corrected entry points, reducing the velocity gap. These players now enter less undervalued and require less upward correction.
The prime cohort (19–34) presents near-zero average velocity, but this masks internal polarization. Rising amateurs and plateauing intermediates coexist. Some ambitious players fight uphill against undervalued newcomers while others quietly leak points to the same demographic pressure.
Established players (35–49) experience slightly negative velocity. When facing underrated youth, they extract less value from wins and absorb greater penalties from losses. Post-compression improvements are marginal, and the disadvantage persists for the core adult demographic.
Seniors (50+) absorb the steepest velocity decline. This cohort pays the largest share of system correction, effectively funding junior convergence.
The diverging paths highlight the mechanical nature of this transfer. Biological factors explain why youth cohorts improve faster, but the sharp post-compression velocity reduction among juniors is consistent with only partial clearance of rating lag.
If this deflation tax exists, we should see systematic rating flow between countries too, not just between age cohorts. Or at least that's the assumption behind a global unified rating system. If this deflation tax is real and measurable between countries, then we're looking at a deep fracture in the rating system.
When a 1900 isn’t a 1900 everywhere
In cross-border games, federation predicts performance better than rating. Remember, we have no information about a player's true strength in relation to the global pool until they face international opponents. In 2025, more than 80% of FIDE-rated chess was played between players representing the same federation. In math terms, this leaves us with a sparse graph where connections between countries carry little information. This is not ideal, as it means ratings can't calibrate properly between isolated pools. FIDE treats every federation as part of a single pool, but traveling players know that a 1900 in Germany is not a 1900 in India.
I ran a recursive, travel-adjusted model on nearly ~200k cross-border classical games from 2025 to isolate the true signals of underrating and overrating. To make it interpretable, here's a map of that:
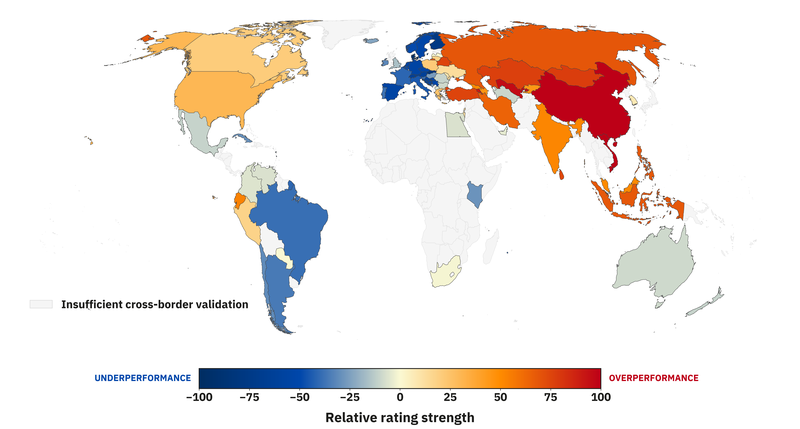
Vietnamese players outperform their ratings by 101 Elo. Chinese players by 100. Uzbek players by 96. Conversely, players from Switzerland (-64) and Austria (-64) underperform when facing foreign opposition. A 1900 in Hanoi carries competitive strength a 1900 in Vienna does not. Same number, different skill. The pattern also appears across longer horizons, which is consistent with persistent local mispricing rather than one-year noise.
Countries that are not as well connected globally don't have reliable signals, and I erred on the side of caution when plotting this. "How does this method actually work?", you might ask.
Why travel exposes the truth
Imagine you are measuring heights using a rubber ruler that has been stretched out. In some countries, the ruler is stretched more than in others. If you only inspect raw game outcomes, you see deviations but cannot yet separate player strength from ruler distortion. Weighted-recursive adjustment sharpens it.
We can look at deviations from expected scores and translate that into a final interpretable metric. The map plot uses the following algorithm:
1. Weighting identifies which measurements are most reliable. A near-even game carries more information than a heavily lopsided pairing. Even certain outcomes on paper should still contribute. For the mathematically-inclined people, I am using a logistic weighting per game W = E(1-E), capped at 90%-10% odds so that even the most imbalanced pairings still carry some information.
2. Recursion is like checking rulers against other rulers. If a player from India beats a player from Spain, and that Spanish player then beats a player from France, those links carry information together. The model updates federation estimates jointly until the full picture stabilizes. In practice, this algorithm converged after 5 iterations to a deviation of less than 0.1 Elo. It also performed better than a first-order model on a held-out set.
3. Elo scaling makes the output usable. Few readers benefit from “Vietnam scored 12% better than expected.” It is clearer and more practical to say “Vietnamese players are underrated by about 100 Elo.”
This approach reduces guesswork. Instead of labeling federations by intuition, it estimates hidden local strength from cross-border results using one consistent ruler.
Serbia: a quick case study
Serbian players face Germans at near parity with a gap of -8 Elo across roughly 300 games. Against Turkish players, the gap widens to -127 Elo. Against Indians, -101 Elo. Against Mongolians it reaches a substantial -171 Elo.
Serbia acts as a convergence corridor where external undervaluation gets corrected through direct contact. Visa-free access and lower travel costs draw many Asian players there. For undervalued juniors, this path is rational, but for the local Serbian pool, the correction burden keeps accumulating.
Strategic crossroads
If you’ve read this far, the picture should feel less mysterious. The opening scenario was not bad luck. The age-cohort split is not random noise. The federation gaps are not isolated anecdotes. They are all different views of the same mechanical reality:
Modern chess is running a single global currency across partially disconnected local markets.
When those markets drift, the correction happens over the board and affects real players. The important point is not that juniors are “stealing” rating, or that one federation is “better” than another. Improvement is real. Geography is real. Demographics are real. A rating system must absorb all of that. The issue is simpler and more structural. The calibration mechanism is no longer keeping pace with the speed at which the player pool evolves.
When entry ratings lag true strength, someone must pay the adjustment. When domestic pools drift apart, cross-border games become settlement transactions. Elo is doing exactly what it was designed to do, except it was designed for a smaller and more homogeneous ecosystem. Today’s pool is none of those things.
So what are the practical consequences?
- A draw that feels correct can still cost rating because the expectation curve is misaligned.
- Adult cohorts quietly subsidize rapid junior convergence.
- Traveling players act as bridges between rating islands.
- The same number can represent meaningfully different competitive strength depending on where it was earned.
That does not mean the rating system is broken beyond repair. In fact, the encouraging takeaway from the data is the opposite.
These distortions are measurable. Measurable problems can be fixed with numbers.
For now, the most useful takeaway is awareness.
If your rating feels stuck...
If certain pairings feel unfair on paper...
If international results don’t match the numbers...
You are not imagining things. You are seeing the system’s adjustment process in action. And that raises the real question for the chess community:
Should a global rating aim to be historically stable or continuously recalibrated to reflect how the game actually evolves?
That conversation belongs to players, arbiters, federations, and analysts alike. My goal here is simply to put a clear mechanical picture on the table and invite scrutiny.
If you’ve experienced rating stagnation, cross-border surprises, or patterns that match what you’ve read here, I’d genuinely like to hear about it. Real tournament stories are often the first signal that something structural is happening beneath the surface.
Chess has always evolved faster than its institutions. Ratings are no exception. Currently, it is lagging behind a rapidly changing demographic landscape.
And lag, unlike luck, is something we can measure and eventually fix.
Where this analysis goes next
If this article explains why rating distortions happen, the full book explores how to fix them. If you’re curious how a global rating system could recalibrate without throwing away Elo’s foundations, The Rating Revolution examines the problem in depth.
Read it, challenge it, disagree with me, but let’s push this conversation forward. I'll be monitoring the comments section below to answer any questions about the methodology!
Check out The Rating Revolution by Vlad Ghita at https://vladchess.com/rating-revolution, with a foreword by GM Levon Aronian.
If you’ve experienced rating stagnation or patterns that match what you’ve read here, please reply in the comments. I read every story.
You may also like
 thibault
thibaultHow I started building Lichess
I get this question sometimes. How did you decide to make a chess server? The truth is, I didn't. Vlad_G92
Vlad_G92Obituary: GM Daniel Naroditsky (1995-2025)
Daniel Naroditsky passed away at the age of 29 in Charlotte, NC, where he resided since 2020. Vlad_G92
Vlad_G92How to Select a Chess Coach: A Complete Guide for Players at Every Level
Finding the right chess coach can accelerate your improvement dramatically. However, with hundreds o… Vlad_G92
Vlad_G92FIDE Ratings Revisited
Do they offer the full picture, or can improvements still be made? ChessMonitor_Stats
ChessMonitor_StatsWhere do Grandmasters play Chess? - Lichess vs. Chess.com
This is the first large-scale analysis of Grandmaster activity across Chess.com and Lichess from 200… GM Avetik_ChessMood
GM Avetik_ChessMood