
Exact Ratings for Everyone on Lichess
I got tired of caring about ratings. So I spent a whole week analyzing all ratings on Lichess. Here are my results.There is lots to explain but first let's skip right to the fun part, you can download the full rating lists here:
Blitz Bullet Rapid Classical UltraBullet Correspondence
Some Ratings
Some of these ratings are uncertain, keep reading for an explanation.
Blitz
| Rank | Title | Player | Rating |
|---|---|---|---|
| 1 | BOT | LermerBot | 3953.7 |
| 2 | BOT | ProteusSF-Turbo | 3908.3 |
| 3 | BOT | liaomin | 3781.1 |
| 4 | BOT | VariantsTop | 3730.1 |
| 5 | BOT | LeelaMultiPoss | 3724.6 |
| 82 | Bobby_Fischer_2800 | 3305.8 | |
| 84 | GM | Pon4ik2006 | 3268.2 |
| 85 | GM | may6enexttime | 3231.0 |
| 91 | GM | Jepetto | 3175.6 |
| 96 | Gaius_Baltar | 3057.7 | |
| 102 | AnythingButAverage | 2997.1 | |
| 103 | HKZ2020 | 2992.5 | |
| 105 | ChessLike273kskpss9 | 2953.0 | |
| 106 | InvisibleGuest2023 | 2946.4 | |
| 107 | GM | NeverEnough | 2935.9 |
Bullet
| Rank | Title | Player | Rating |
|---|---|---|---|
| 1 | BOT | liaomin | 4076.1 |
| 2 | BOT | LermerBot | 4068.4 |
| 3 | BOT | EdoBot | 4024.3 |
| 4 | BOT | VariantsTop | 3979.7 |
| 5 | BOT | LeelaMultiPoss | 3954.2 |
| 94 | dr_xcommander | 2964.5 | |
| 97 | GM | penguingim1 | 2954.7 |
| 98 | GM | nihalsarin2004 | 2948.4 |
| 100 | GM | ARM-777777 | 2938.6 |
| 101 | GM | Night-King96 | 2925.2 |
| 104 | GM | may6enexttime | 2892.0 |
| 105 | GM | LastGladiator2 | 2882.3 |
| 107 | GM | Arka50 | 2866.6 |
| 108 | GM | legendreturns | 2860.9 |
| 109 | GM | KontraJaKO | 2853.8 |
UltraBullet
| Rank | Title | Player | Rating |
|---|---|---|---|
| 1 | GM | nihalsarin2004 | 2903.7 |
| 2 | GM | penguingim1 | 2851.7 |
| 3 | IM | OhanyanEminChess | 2845.7 |
| 4 | FM | Blazinq | 2829.4 |
| 5 | FM | tamojerry | 2792.2 |
| 6 | catask | 2791.0 | |
| 7 | FM | aaryan_varshney | 2763.9 |
| 8 | GM | chessmaster2006 | 2754.6 |
| 9 | NM | ShadowKing78 | 2741.7 |
| 10 | FM | Ragehunter | 2740.0 |
What?
Some of you may know that Lichess doesn't use the Elo rating system. It instead uses Glicko-2 which produces more accurate ratings. Both Glicko-2 and Elo operate on a similar scale. This is mathematically defined as follows:
Δ = player1_elo - player2_elo
Expected win rate = 1 / ( 1 + 10 ^ (-Δ/400))
This means that if you are 100 rating points above your opponent, you should expect to score 64%. If you are 200 rating points above your opponent, you should score roughly 76%. (In the case of Glicko-2 it's a bit more nuanced, but that's out of scope for this blog post)
Glicko-2 and Elo work as functions of the current game outcome. That is, they take in your rating, your opponent's rating, and the game result, and in turn spit out a new rating for you (again I am oversimplifying Glicko-2 here). This system allows for your rating to be updated after each game. In theory, if everyone continues to play indefinitely, the ratings will eventually approach their 'optimal' levels.
But it is possible to skip right ahead to the optimal ratings. Or at least, the optimal ratings for a given period of time. Here I have taken the month of November 2023 in the Lichess database, and I have calculated the "optimal" ratings using the program Ordo.
Ordo works by guessing every rating, and then gradually improving the ratings until they converge on the best possible values. This way, the ratings produced are more accurate than the Glicko-2 ratings in between games. Ordo is mainly used for rating chess engines, whose skill level is always constant. For humans, this is not the case, hence we limit ourselves to one month. Of course it is possible to improve over the span of a month, but most intermediate players will not improve by more than 50 points, if I had to guess.
Why?
There are many benefits to such a system, but also some drawbacks. I really like the idea of generating ratings like this, because it addresses some of my biggest gripes with online chess (and even more so over-the-board chess).
Some Advantages:
Rating farming
An annoying aspect of online play, especially at very high levels, is when players care too much about ratings. This is obviously unavoidable, and it would require great mental discipline not to feel bad about dropping one's rating, and good about increasing it. Caring too much about ratings often leads to people avoiding "underrated" players, and playing "overrated" players. Once someone farms up a high rating, he may avoid any opponent who he perceives to threaten his rating, but he will also be avoided by those who do not wish to be "farmed". This results in players mentally calculating whom to play and whom to avoid.
With optimal ratings, you would not get punished to the same degree for playing "overrated" players. This is because all the games are calculated at once, and not as a sequence. So every single game you and your opponent played this month will be counted equally, no matter who was doing better or worse at the time you played it. There would be no such thing as a hypothetical "Hikaru got his rating really high, but then he played Magnus and lost it all".
Another aspect is that people strive to achieve a milestone rating, and then stop playing. We will see that this is very apparent in Lichess's rating distribution. I have often been guilty of this myself, whenever I hit 1900 or 2000 in a given category, I take a break and focus on a different time control, or stop playing altogether. All of this focus on the fluctuations of one's rating distracts from the game itself. I have often found myself thinking "I'm so close to beating this guy, and he is 150 above my rating, this is really good!", or "I can't lose to this guy, he is rated 100 below me".
This brings up another point, there is a disdain by higher rated players of playing lower rated players. Losing to someone 300 below your rating will cost you lots of points. And it is less stressful to simply not play them. In over-the-board chess especially, I know that a lot of players feel it's a "burden" to play relatively weak players because of the risk of losing a lot of points. All these worries about your rating aren't just because of ego, but can also have real consequences in over-the-board play, such as which tournaments one can play in.
By taking away the fluctuations, and calculating a set of ratings for a set period of time, all these worries and strategies can be greatly diminished. You no longer need to strategize about who to play, or worry about your opponent's rating. All will be evaluated fairly by the rating system.
Accuracy
This is a pretty simple point. By using a tool like Ordo, we are practically cheating by finding the "perfect" ratings. I compared Lichess and Ordo ratings for the Blitz games of November. Lichess ratings predicted 58.423% of decisive game outcomes correctly, Ordo predicted 59.527% correctly. Remember than a coin flip can predict 50% of decisive outcomes correctly, so 58% is already very good. If Lichess was using something as archaic and unreliable as FIDE's Elo version, I doubt the predictions would be accurate more than 53% of the time, pretty much random. Yet Ordo performed 13.1% better than Glicko-2.
Having helped many new players get started with chess, I am now used to seeing every new players journey of losing their first 10 to 50 games in a row, before eventually getting paired with someone their level, in the 400 - 600 range. (Thank you Lichess for lowering the rating floor to 400 from 600! It really helps weaker players). These ratings also don't have a ceiling or floor. I would argue that the current floor on 400 on Lichess is still not low enough, we will see later than many players of differing skill levels are all at 400. This can especially hurt younger players, I know that when brother was 5 years old and started to play, he had a hard time finding equal opponents. (Maybe chess.com isn't so bad after all if you are really bad at chess and need someone to play.)
Imagine a hypothetical chess site that calculated optimal ratings every day, and seeded Glicko-2 ratings for the day with those. New players could actually choose whatever rating they want to start on. It would not inflate the ratings of others, or negatively affect the rating distribution. If you're a 500, start at 500. If you're 2500, start at 2500. It's that simple. When the day is over, your rating will get updated to it's appropriate level.
Bot ratings
Lichess bots are very underrated, so people often avoid playing them in rated games. The best bots on Lichess are a lot better than the best humans, yet their ratings are not much higher. This is because most of the top human players have better things to do than getting farmed by a 4000 Elo bot. These bots often play each other, and slowly extract ratings points from the player-base through playing lower rated bots. Lichess also limits ratings to 3999, so even if bots were able to get up their ratings, they would still be capped. Why is this important? First, it would be more fun to play bots in rated games, and have them in the same player pool as humans. Secondly, in computer chess, ratings are usually seeded on engine performance in real games against top human players, this is why Stockfish can be considered 4000 Elo and so on. By calculating exact ratings, we can see precisely how much better than us mortals these machines are. It is also pretty fun to find bots near your rating level in my rating list, give it a try!
Cheaters
When someone cheats on Lichess, they are stealing rating points from players. When they get banned, Lichess refunds those rating points. Of course, Lichess doesn't go back in time an recalculate all ratings; that would be impractical. But with optimal ratings, cheaters aren't stealing anything, they are merely wasting their time, and if anything, making the ratings more accurate. But even if a cheater manipulated ratings, their deletion from the game pool will make it as if they never existed in the first place.
Fake ratings
It is very easy to get rated 3900+ on Lichess by making a bunch of dummy accounts and have them play each other. Then strategically lose games to new accounts to boost them. Repeat this and you will get any rating you want. And then you will get banned. This is against the rules, and would be impossible with a rating program like Ordo. To receive a rating on Ordo, you must have played against the 'major group' of players. You cannot simply play within your own small group and expect to have a rating that corresponds to the main group. Even if you did play one game against a normal player, your rating would still be highly uncertain, and anyone who has only beat you would receive an even more uncertain rating.
Another flaw, this time specific to Glicko-2, is so called "Volatility farming", you can read more about it here. Sure it is against the rules to do this kind of manipulation, but a smart player could do this in a pretty undetectable way, or at least in a plausibly deniable way. By strategically losing and winning games, you can make your rating very volatile, and then when you start playing normally at your full capacity, you will see big gains say +30 points per game, where as most stable rated players will only see their rating change by +-8 or so, when playing equals.
This is another problem with Glicko-2. When you have played too many games, your rating becomes very stable, and players will often perceive that they are stuck at that level. Suddenly, by creating a new account, you can reach a much higher rating.
Some Disadvantages:
Live ratings are fun!
I don't want to claim that live ratings should be abandoned, it's a lot of fun to see your rating update after each game (at least when it goes up). But for organizations like FIDE, continuing to adhere to an outdated and inaccurate system, when they only update their ratings once per month anyways... yeah it's pretty dumb. The fact that it is soon 2024 and you still cannot access all chess games online for free is baffling.
Ordo is sloooooow.
If anyone technically knowledgeable is inspired by this write-up to try Ordo, please please build it from source and modify the Makefile to actually apply optimizations at build-time. All current versions of Ordo are 2x as slow as they need to be!
But even so, the blitz ratings published here took 11 hours to calculate. This is not very scalable and I am working on improving Ordo to make it much faster. In the future I can imagine a world where ratings are calculated on a sliding window of the past 30 to 90 days, and updated daily.
If you wanna help me improve Ordo, DM me and get in touch. I will be calculating next month's ratings, but working through the backlog will take astronomically long with the current version of Ordo. I imagine if this gains traction, I could make a website where one can see their Lichess Ordo rating month-by-month, or even week-by-week.
Confidence intervals are even slower
Ordo can produce a confidence interval for a rating. Someone who has played hundreds of blitz games might have their rating be ±20 (with 95% certainty), but someone with only 3 games will have a ±300 rating. Ordo calculated these values by running lots of simulations, which on the scale of the Lichess game database would take forever to calculate. Much longer than the actual ratings. Again if you're smart and want to help out, please get in touch.
For the leaderboard, it would make sense to filter players with uncertain ratings, which is what Lichess does, but that was not something I could do right now so I settled for excluding players with <10 games. This is not perfect, and some players on the current leaderboard were very lucky, or simply played unusual opponents. Please do not accuse the top performers of cheating just because they are high up.
Dear Lichess
Please release the database weekly instead of monthly. It would be more accessible to download (and seed), and would give you smaller bandwidth usage peaks. And it would help me update these ratings every week, no one wants to wait a month to see how they improved.
Now some cool graphs
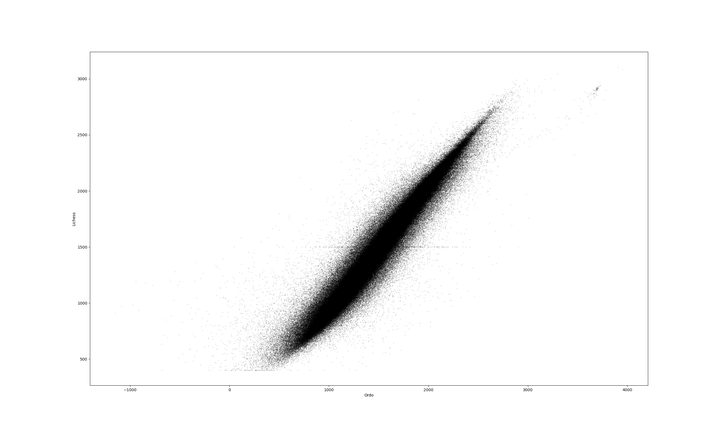
Here we see the Ordo ratings for Blitz, plotted against Lichess ratings. It is hard to convey that there are nearly a million points in this plot. Most of the ratings are actually in a very narrow band right in the center; Lichess has very accurate ratings. We can see lots of outliers though. We have first a bunch of users who stop at specific milestones. We have a cluster of bots up by themselves. They are much better than the top rated humans, but have the same ratings. And we can see a trail of bots leading back to the main cluster, from where they slowly exfiltrate rating points. We also see the rating floor at 400, where a lot of players of differing skill levels are stuck.
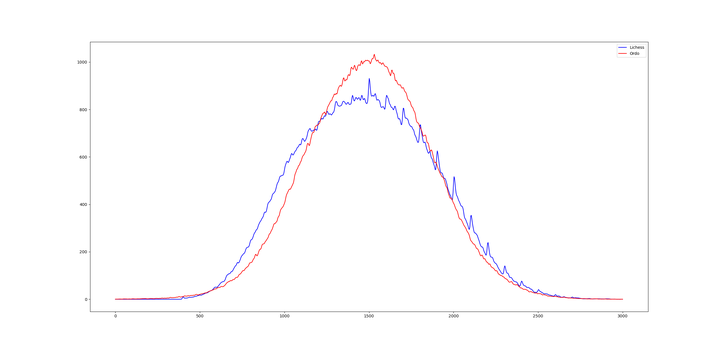
Here we see the nice bell-curve of Ordo ratings, compared to the less nice bell-curve of Lichess ratings. We see how a lot of users stop playing at milestone ratings. We can also notice that there are more really good players than really bad players (also because bad players are less likely to keep playing). I suspect that this will lead to rating inflation over time, because higher rating correlates with playing more. This defect does not exist on Ordo.