
A better game clock history
Storing precise move times: science to the rescue
Thanks to the hard work of isaacly and revoof, lichess now stores precise move times, and can accurately replay the game clocks during analysis.
Lichess clocks always had a high precision of one hundredth of a second, while the game is playing . This has not changed. However, after the game has ended, we now store the historical move times (how long it took to play each move of the game) with high precision. This has several benefits.
Why should I care
Good question, thanks for asking. First of all, on the game analysis page, the move times chart is now more accurate:

Move times are now stored and displayed with a precision of one tenth of a second. The precision even goes up to one hundredth of a second, for positions where the player had less than 10 seconds left on their clock.
Second benefit, the game analysis page now displays the clock states for each move of the game:

How cool is that? Now you can tell if a move was played in time pressure.
Additional goodness
- Lichess studies also received historical clock states. A study chapter will have clock states when importing a lichess game, or when importing a PGN that contains the {[%clk 0:15:23]} clock notations.
- PGN exports of all games and study chapters now include the clock states, using the same {[%clk 0:15:23]} format.
- Analysis realtime playback also benefits from the extra accuracy. Now we can replay the games exactly as they happened!
Technical considerations
Let us take a peek under the hood with @isaacly.
Lichess used to store a rough estimate of your move time. Each move was rounded to one of 16 values, all between 0s and 60s. This format consumed just 4 bits per ply, but had drawbacks:
- It's not accurate enough to estimate clocks or determine if a player was in time pressure.
- It works best for blitz -- more extreme time controls might have many moves rounded to the same value, which results in a flat move time chart and not-so-real realtime playback.
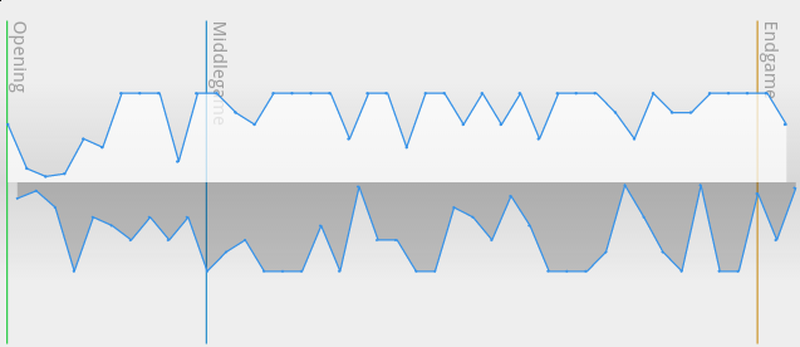
Old: A 45+45 game by prune2000, with most moves recorded at max 60s value.
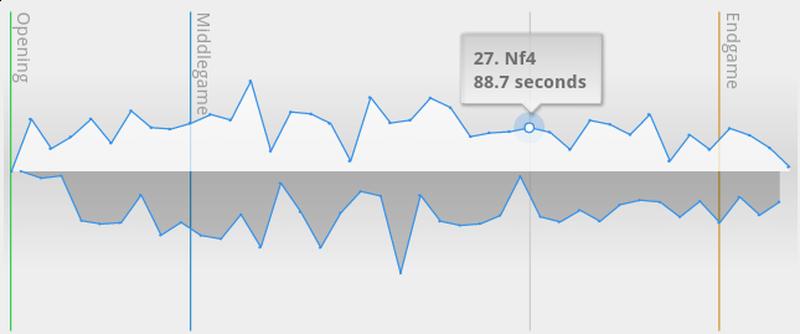
New: A more recent 45+45 game illustrating richer variation in pace.
Our new format stores clocks -- move times are calculated on the fly. This means that there's no drift in clock precision over time -- the clock of every move is stored and retrieved with high precision. It also puts most of the gritty math into the read operation, which reduces the risk of storing incorrect data.
Most clocks are recorded with a precision of .08s (.02s average error). But the storage format allows us to selectively store some moves with higher precision. Clocks under 10s and the last time in the game are stored with 0.01s precision.
The new encoder manages to pack all this extra information with only a 2x increase in storage requirements -- using around 8 bits per ply. We were able to achieve this rather impressive result by making sure certain play styles (consistent move times) are especially cheap.
The algorithm has two distinct stages which it uses to convert its input of clock times into bytes. Each data transformation is reversed in the decode routine which converts bytes back into an array of clock times.
Stage 1 Convert the input into an array of smaller integers -- reduce the total sum of the input.
Stage 2 Write this array to bytes using a variable length encoding. Very small values can be recorded in 6 bits.
Stage 1 reduces the absolute size of values in the input array, using assumptions about how most games are paced. Our estimation step requires storing each side separately.
- Truncate bottom 3 bits, but selectively save these for certain moves. The truncated bits have high entropy and cannot be compressed.
- Recursively estimate each value by taking a weighted average of its nearest already estimated neighbors.
- Estimate end time based on number of moves and time control.
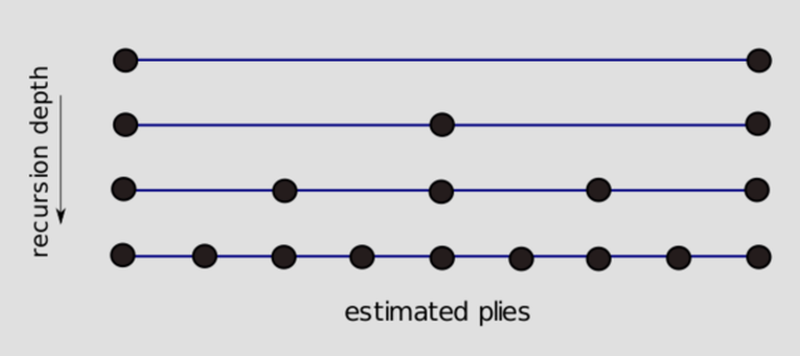
The Stage 2 varint writer uses a fixed schema (5 bits initially, and then groups of 3 bits until the number is written), which was empirically determined to have good properties using a large sample of existing chess games.
Although Lichess isn't normally bottlenecked by CPU, storage formats are hard to change, so we wanted to come up with a stable format that could be efficiently encoded. The module was heavily optimized and runs entirely without integer division (preferring estimations that can be accomplished with bitshift) and uses Java's nio.ByteBuffer to efficiently cast data between types. In the end, the entire pipeline uses about 24 cycles per ply, requiring a typical machine just 600 nanoseconds to encode a 32 move game!
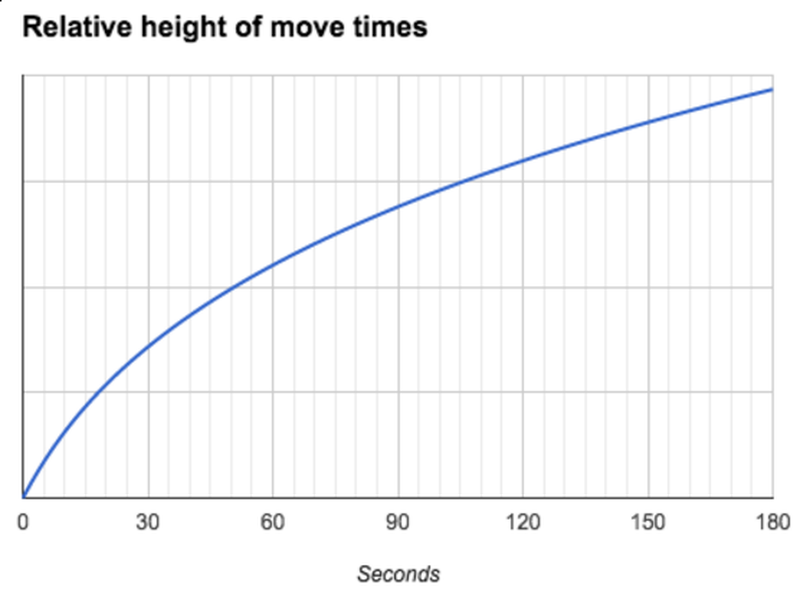
Finally, we adjusted the move time chart to handle a wider range of input to ensure that quick moves are still visible in slower games. The chart is now scaled with a ln2 function which is roughly linear for fast time controls and evens out for longer moves.
We're always looking for ways to improve the site. If you have feedback or suggestions, speak up and let us know. Enjoy!
More blog posts by Lichess
Lichess Game of the Month: March 24
Aggressive English/Reti system with 6.g4!?
Round 14: Gukesh and Zhongyi are officially the World Championship Challengers
A historic finish to the FIDE Candidates, as 17 year old Indian prodigy becomes the youngest World C…
Candidates Round 13: Gukesh takes the lead, Zhongyi pulls ahead
A massive day for the 17 year old Indian, as his chances to win the Candidates skyrockets, as Zhongy…