Guess the rating: adding more variables
using time, evaluation, and evaluation changes.Before reading this post
The games in this analysis were lichess-annotated 1+0 bullet games from July 2023. More about the data can be found at the lichess open database. The study was conducted on games 1+0 without berserk or any time odds. The code can be accessed here. My previous post was on a similar topic. The code can be found here.
Change in data set formatting
In my previous post, all of my dataset was formatted differently. The longest game move number-wise played in all 1+0 bullet games was 173 moves. I wanted to include 3 information in every move: evaluation, evaluation change, and time. All X dataset was formatted in the following way. All Y dataset (the result) was the average rating of the black and white player.
| 1 (White) | 1 (Black) | ... | max(White) | max(Black | |
|---|---|---|---|---|---|
| Eval | 0.0 | -5.0 | ... | 11 | -11 |
| Eval Change | 0.0 | -5.0 | ... | 0 | -22 |
| Time | 60 | 60 | ... | 10 | 2 |
I went through some personal hyperparameter tuning and decided on using data till move number 60. Including every move till 173 filling all the missing values from games with 0 resulted in several problems (inflated data size by 3 times, slower convergence leading to slower training, higher training, and test loss).
Every game was formatted to 3 rows x 120 columns (60 moves per color) x 1 channel. The whole dataset included 955173 games and 2% of the dataset (19119 games) were left out for testing. I divided the training set into 27 portions. Some of which will be included in the code.
Process
I decided to make 3 models: An arbitrary neural network of my design, a transfer learning model from vgg16, and a linear model regressor with incremental learning ability. We will call these personal, vgg16, and PAR (passive-aggressive regressor) in the result section. For the transfer learning model with vgg16, it had to meet the requirement of at least having 32 x 32 x 3 channels which was completed by copying the same dataset 11 times rowwise and 3 time channelwise. For linear models, the ability to incrementally learn was important which led to choosing the passive-aggressive regressor. The models can be checked in the GitHub here.
Every model was trained with 10 epochs on the training set.
Results and Discussion
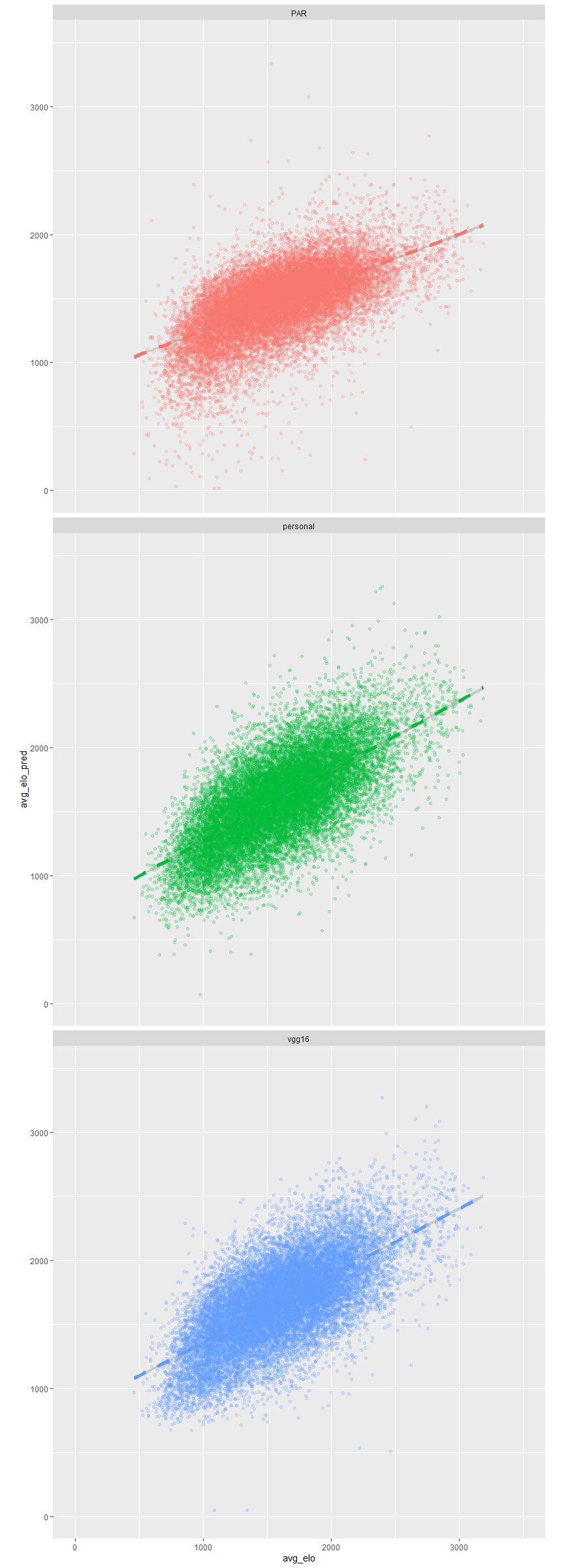
All the models detected some relationship between the dataset and the average rating. However, we can see that the slope of the model is smaller than expected (We expect it to be 45 degrees if it is a perfect model). The model order is PAR, personal, and vgg16 (open in another tab for a larger image).
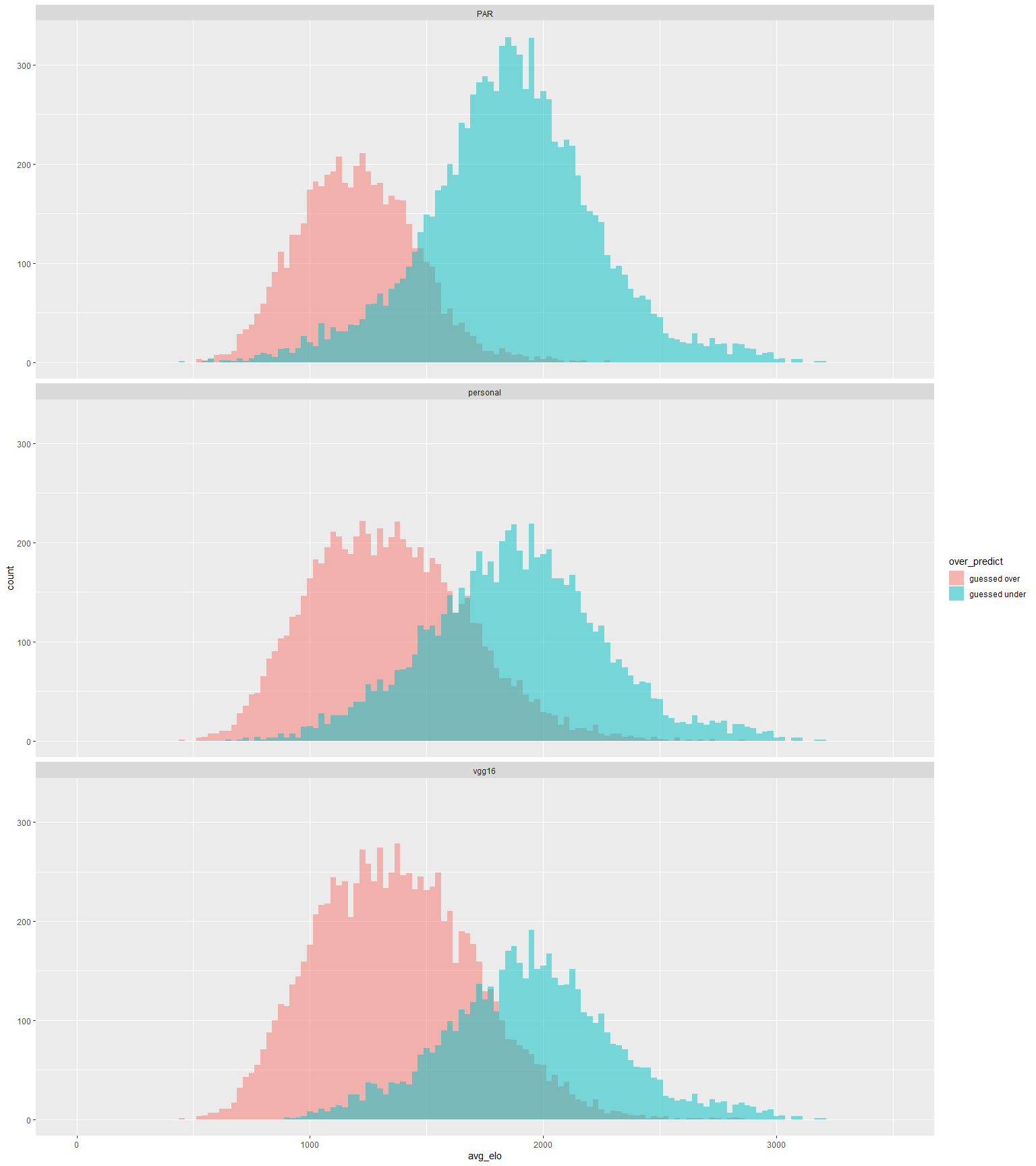
The common thing about all 3 of these models is that they tend to over-predict lower ratings and under-predict higher ratings. The following are the distributions in which they over or under-predicted the rating by 100. Red is guessed over, and Blue is guessed under.
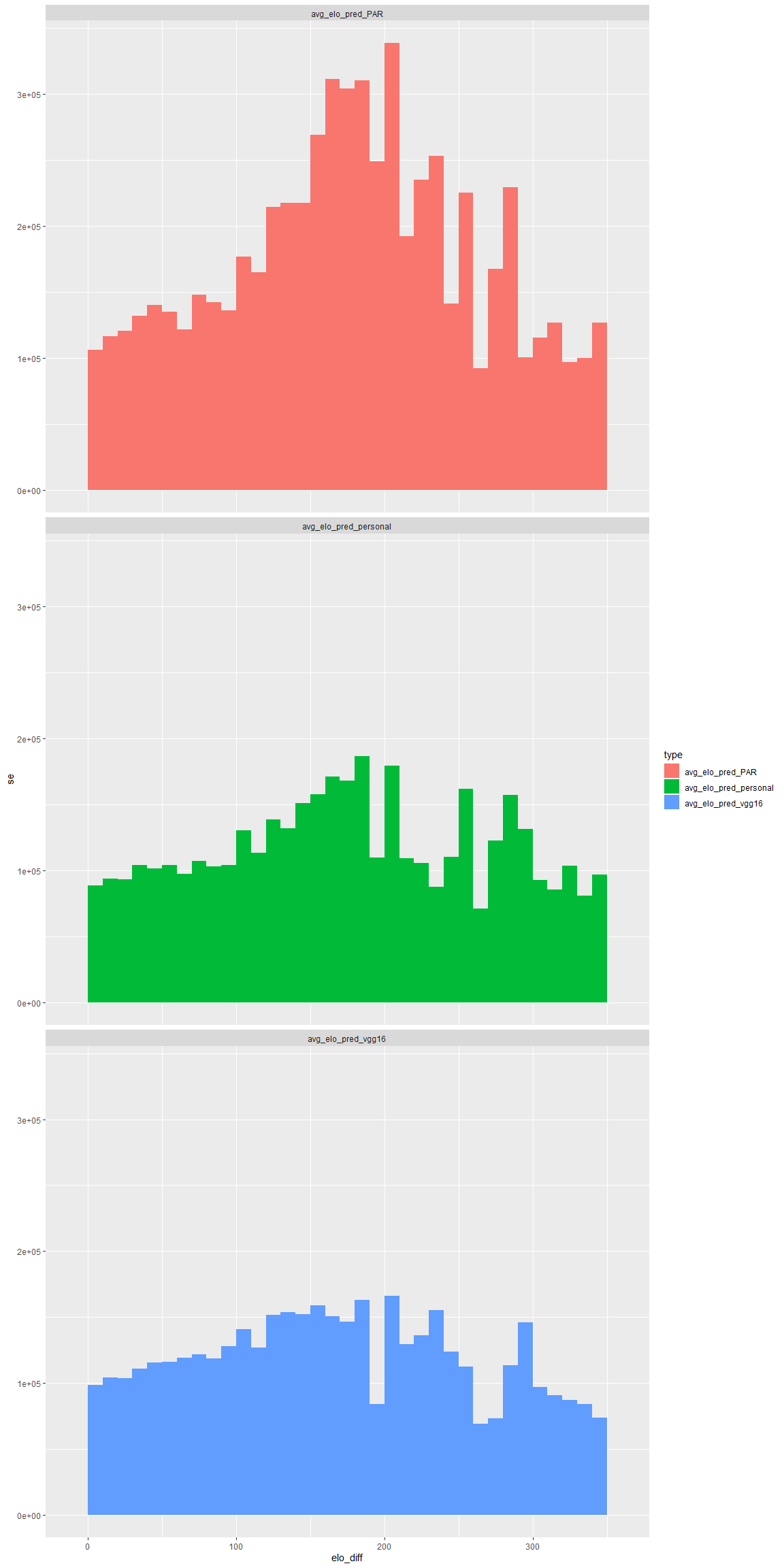
The next question revolves around in which situation these models have a hard time accurately predicting the average rating of games. First, the amount of raw data drops around 1000 and 2000 rating. Since mean squared error focuses less on the lower population, the model would have cared less about the tail ends of the data.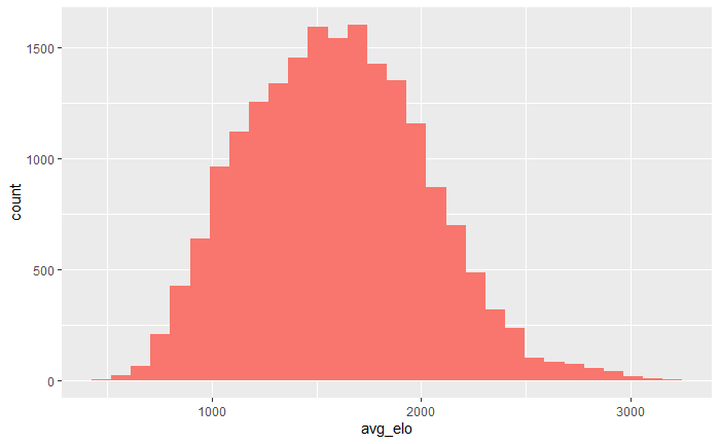
There was another interesting insight related to the rating difference between players and the error of the model.
| Average error when rating difference between players | PAR | personal | vgg16 |
|---|---|---|---|
| was ±50 | 1.26 | 1 | 1.11 |
| was 50-100 | 1.44 | 1.09 | 1.27 |
| was larger than 100 | 1.87 | 1.27 | 1.28 |
The average error seemed to have an increasing relationship with the rating difference between players in a given game. Although this is not enough to fully explain the error, some of the error can be attributed to the problem of guessing the average of both players.
Conclusions
ML models did guess ratings to some extent given the set of information. The models found much more correlation between the data than the previous post where they weren't able to find any correlation. Probably this project can be extended in a way such that you can give multiple games of a person and make the ML model guess the rating of a player.
The linear model (PAR) performed the worst among all the models. The other two neural networks performed similarly but vgg16 performed worse. This may be due to the fact that vgg16 was developed for image datasets and my dataset was artificially copied 33 times to just satisfy the input requirements.
In addition, guessing the average rating of gameplay has its own problem. If there is a large rating difference between the players, it is hard to detect where the game belongs. My original project was to get two outputs, white and black ratings but this caused a lot of confusion and errors in the model itself. Probably there are better model designs and a lot more hyperparameter tuning you can do to increase the accuracy of the model but I will leave it for next time.
Final Remarks
From my last post, I saw a lot of comments talking about giving more information to the models. I agree that would have been a good idea. However, the effort was to use a minimal amount of information. Sometimes, ML models find insights that are hard to comprehend and I thought it was worth trying. I will continue working with ML but might reduce the proportion of ML training posts since they tend to take a lot of time and resources.
More blog posts by oortcloud_o

Linking top players based on openings
Using relatedness network on opening choices of top grandmasters
Which openings are related?
simulating opening connectivity graphs with known techniques
A short literature review
chess opening similarity and more