
Guess the player with Elo, Evaluation, and Time
ML model for identifying players with only Elo, Time, Evaluation.Before reading this post
The games in this analysis were lichess-annotated 3+0 blitz games from June 2023. More about the data can be found at the lichess open database. The 20 players with the most games were chosen for this study.
Motivation
My motivation for doing this analysis was actually not to identify players. I was trying to find a way to group players. For instance, some players have strong tendencies to berserk given a chance. Some will never berserk and will go for longer games.
Player 1 loves berserk, plays a tone of moves and their game does longer even to move number 90.
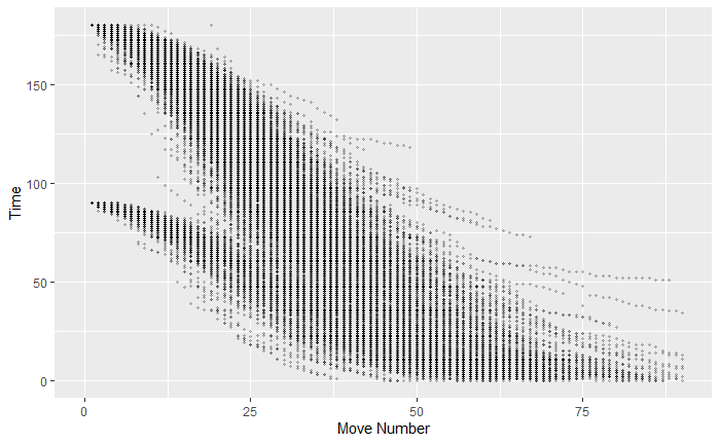
Player 2 on the other hand players slowly in the middle game and runs lower on time with low move numbers.
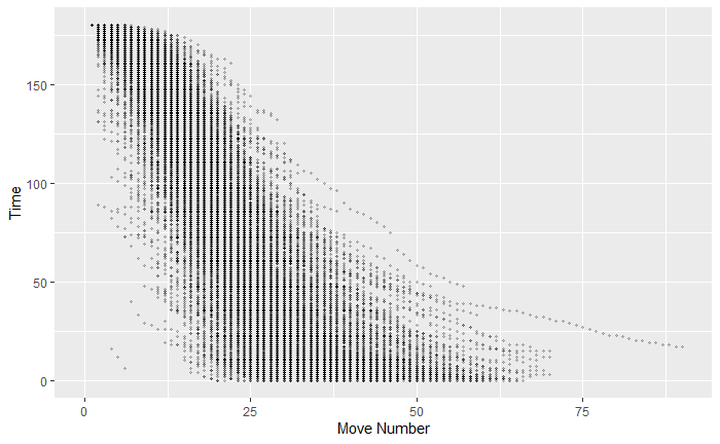
From these analyses, I wanted to answer a question. Can I identify players from the games that they played? Since the above analysis was devoid of the position, I did this analysis without information on piece movement. (My data did not have any e4, Pawn moved, Knight was captured, etc.)
Each game on this dataset had the following information: Move Number, Time, Eval, Move Type (blunders and such), Time Spent, Elo of the player, and Result of the game.
Analysis
I chose the 20 players who played the most 180+0 games. All their games were formatted so that Evaluation, Time on move X was preserved. I included Time Spent and Move type (Blunder, Mistakes, Dubious, Normal moves) which was encoded to (3, 2, 1, 0). This was an arbitrary choice of encoding and the variables related to move type and time spent were removed later in the study. I will do a future study on how to encode move types properly. Each game was processed into one array in the following format. maxlen was the longest game in my database. Each one of these were considered as variables.
[win, elo, type_1, eval_1, time_1, time_spent_1, type_2, eval_2, time_2, time_spent_2, ..., type_maxlen, eval_maxlen, time_maxlen, time_spent_maxlen]
I first started with training a Random Forest Classifier using all variables. The reasoning behind this is to get the feature importance of all the variables. The feature importance list goes as follows:
1. Elo, 2. Eval_1 (Evaluation at Move Number 1), 3- 8 was Eval_2-7, 9. Time_12 (Time at Move Number 12). ... [Eval and Time] ... 53. Time Spent at Move Number 2 (First occurrence of Time Spent) ... 93. Move Type at Move Number 2 (First occurrence of Move Number)...
The classifier had a low 50% accuracy on the test dataset. and gave very low weights on Time Spent and Move Type. The total contribution of each variable in the complete model was as follows.
| variable | elo | eval | type | time | time spent |
|---|---|---|---|---|---|
| contribution | 8% | 34.4% | 8.3% | 29.5% | 19.6% |
Whenever a complex model has low accuracy, the intuition is to make a simpler model and see if it works better. I ended up making 64 models with different variable sizes and kept on with my experiment.
n is the number of variables. I removed some rows intermittently. The graphed version of the table is included below.
| n | test accuracy | cv accuracy | elo | eval | time | type | time |
|---|---|---|---|---|---|---|---|
| 1 | 38.4% | 39.1% | 100% | 0% | 0% | 0% | 0% |
| 5 | 76.6% | 74.5% | 42.1% | 57.9% | 0% | 0% | 0% |
| 9 | 76.7% | 76.4% | 33.6% | 57.7% | 8.1% | 0% | 0% |
| 45 | 67.4% | 66.8% | 20.0% | 46.8% | 33.1% | 0% | 0% |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 514 | 53.1% | 100% | 8% | 34.4% | 29.5% | 8.3% | 19.6% |
I tried to study the effect of the five variables' contribution: elo, eval, type, time, and time_spent. The correlation matrix looks as follows. The most important row is highlighted in bold.
| n | acc | elo | eval | type | time | time_spent | |
|---|---|---|---|---|---|---|---|
| n | 1 | -0.671 | -0.579 | -0.535 | 0.928 | 0.405 | 0.845 |
| acc | -0.671 | 1 | 0.048 | 0.958 | -0.622 | -0.299 | -0.668 |
| elo | -0.579 | 0.048 | 1 | -0.020 | -0.463 | -0.766 | -0.593 |
| eval | -0.535 | 0.958 | -0.020 | 1 | -0.498 | -0.342 | -0.586 |
| type | 0.928 | -0.622 | -0.463 | -0.498 | 1 | 0.252 | 0.774 |
| time | 0.405 | -0.299 | -0.766 | -0.342 | 0.252 | 1 | 0.393 |
| time_spent | 0.845 | -0.668 | -0.593 | -0.586 | 0.774 | 0.393 | 1 |
The improvement of accuracy was strongly negatively correlated with the contributions of type and time_spent which led me to remove the two variables. Furthermore, the two variables were each correlated to existing variables. Evaluation would have reflected the move type and Time would have reflected the Time Spent on a move. The following graphs are to help your understanding. Increasing the number of variables (increasing complexity) the introduction of type, and time spent per move led to lower accuracy.
The graphed version of test_accurcy and contribution over the number of variables.
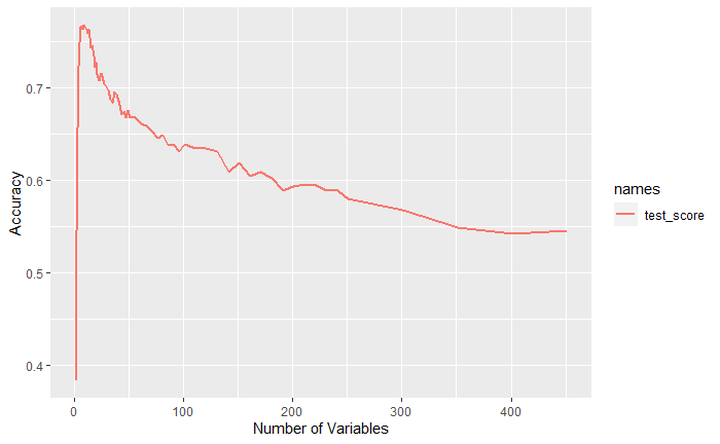
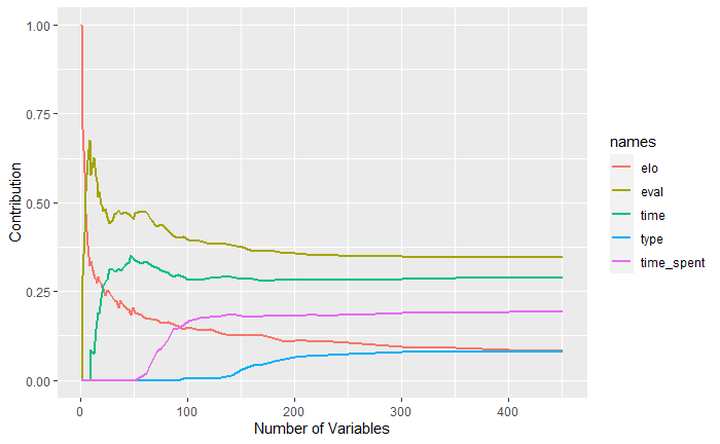
Conclusion
The final model was trained over 9 variables which led to 76.7% accuracy among 20 players. This is not the best result. However, given 20 players with limited variables, I was happy about the result for now.
The variables were: Elo, Eval 1-7, and Time 12.
| Variable | Contribution |
|---|---|
| Elo | 33.5% |
| Evaluations at 1 - 7 | 57.7% |
| Time at move 12 | 8.7% |
If we scatter the moves the player made on a graph, it looks like this. Each player was colored differently.
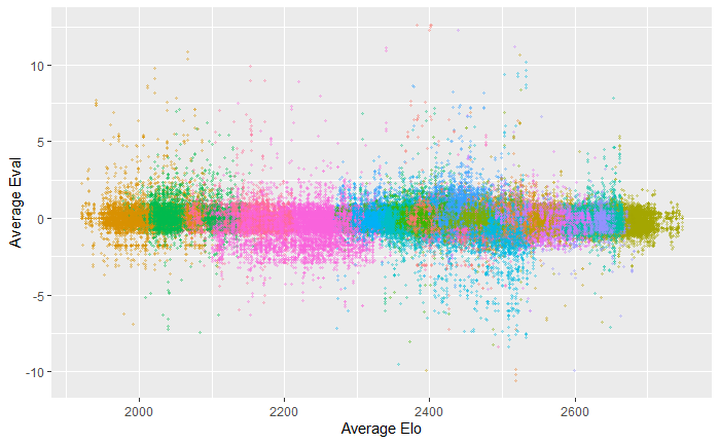
The average of the players looks like this
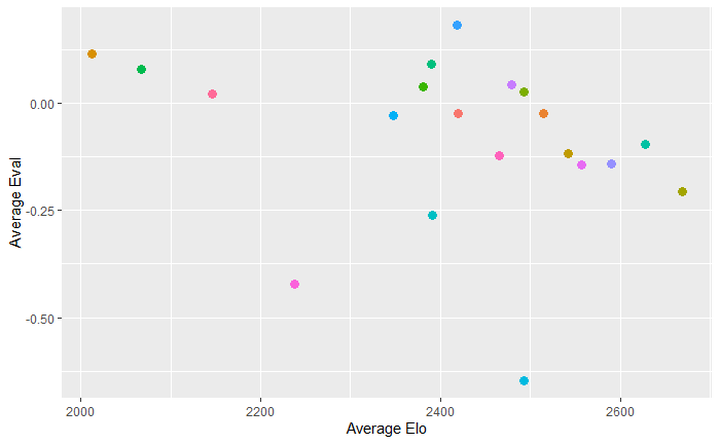
Even we can distinguish some players from others. However, the model found some ways to distinguish some of the harder ones as well. Probably some measure of Time at move 12 was the tiebreaker. Maybe some players had more berserk games?
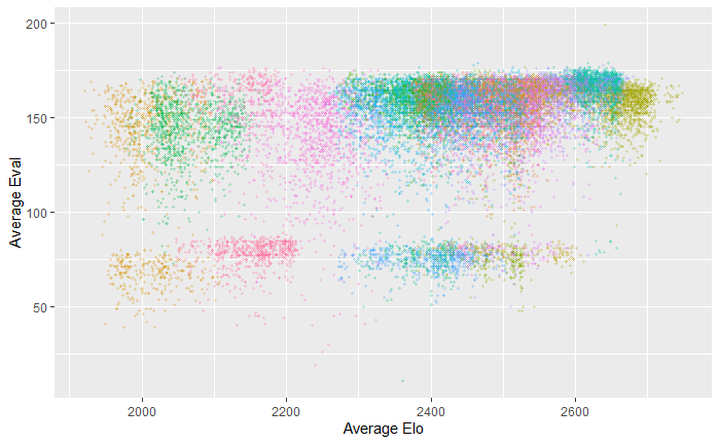
Sidenotes
I have also used other methods such as RFE and variance threshold methods to select the features but they led to not significantly lower but lower accuracy.
Future posts
I am currently thinking of a project to classify players into some groups. This will take a long time. I will keep on working on interesting topics about chess and data. If there are topics you want me to analyze, feel free to ask in the comments. Thank you for reading!
You may also like
 oortcloud_o
oortcloud_oHow long is an opening?
A new approach on where opening ends FM CheckRaiseMate
FM CheckRaiseMateRatings Are Broken
According to statistician Jeff Sonas, lower rated players win more often than they're supposed to. oortcloud_o
oortcloud_oI'm berserking!
should you? oortcloud_o
oortcloud_oLinking top players based on openings
Using relatedness network on opening choices of top grandmasters oortcloud_o
oortcloud_oCheater gameplay? - part 1
How do they differ in 1+0 Bullet games oortcloud_o
oortcloud_o